16.2. Performance Optimization¶
16.2.1. Contains¶
inchecks whether iterable contains valueO(n) -
in strO(n) -
in listO(n) -
in tupleO(1) -
in setO(1) -
in dict
List:
>>> DATABASE = ['mwatney', 'mlewis', 'rmartinez']
>>> user = 'ptwardowski'
>>>
>>> %%timeit -n 1000 -r 1000
... user in DATABASE
165 ns ± 35 ns per loop (mean ± std. dev. of 1000 runs, 1,000 loops each)
Set:
>>> DATABASE = {'mwatney', 'mlewis', 'rmartinez'}
>>> user = 'ptwardowski'
>>>
>>> %%timeit -n 1000 -r 1000
... login in users
103 ns ± 34.4 ns per loop (mean ± std. dev. of 1000 runs, 1,000 loops each)
Note, that the longer our DATABASE is, then the difference is more visible:
List:
>>> DATABASE = ['mwatney', 'mlewis', 'rmartinez', 'bjohanssen', 'avogel' 'cbeck']
>>> user = 'ptwardowski'
>>>
>>> %%timeit -n 1000 -r 1000
... login in users
276 ns ± 90.6 ns per loop (mean ± std. dev. of 1000 runs, 1,000 loops each)
Set:
>>> DATABASE = {'mwatney', 'mlewis', 'rmartinez', 'bjohanssen', 'avogel' 'cbeck'}
>>> user = 'ptwardowski'
>>>
>>> %%timeit -n 1000 -r 1000
... login in users
105 ns ± 35.2 ns per loop (mean ± std. dev. of 1000 runs, 1,000 loops each)
16.2.2. PyPy¶
No GIL
Can speedup couple order of magnitude
16.2.3. Patterns¶
Source: [1]

16.2.4. Tools¶
memray [2]
tracemalloc
mmap - memory allocation
Pytest extension for doing benchmarking
pip install line_profiler
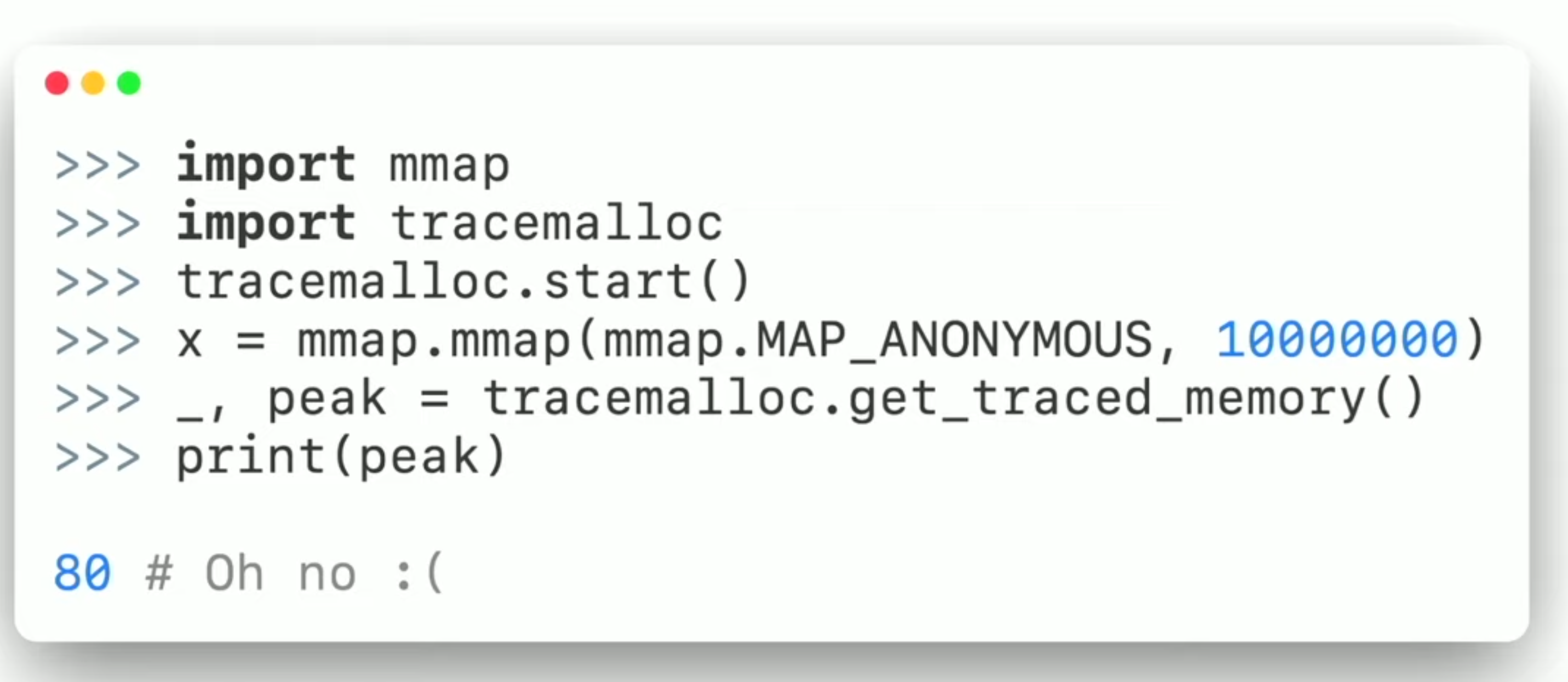
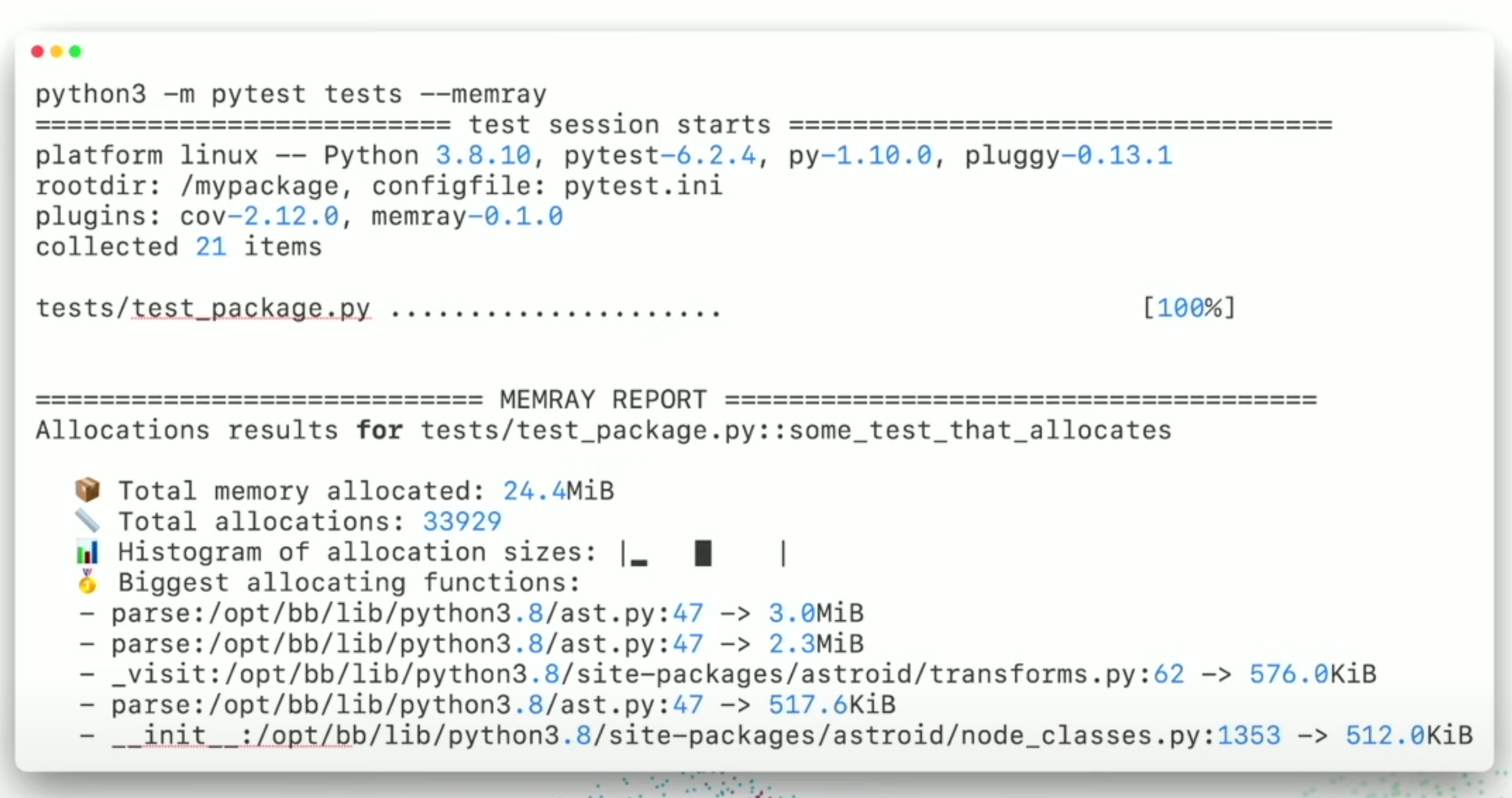

16.2.5. Numpy vectorization¶
Scipy Ecosystem:
16.2.6. Specialized data structures¶
scipy.spatial- for spatial queries like distances, nearest neighbours, etc.pandas- for SQL-like grouping and aggregationxarray- for grouping across multiple dimensionsscipy.sparse- sparse metrics for 2-dimensional structured datasparse(package) - for N-dimensional structured datascipy.sparse.csgraph- for graph-like problems (e.g. finding shortest paths)
16.2.7. Cython¶
types
Cython files have a
.pyxextension
def primes(int kmax): # The argument will be converted to int or raise a TypeError.
cdef int n, k, i # These variables are declared with C types.
cdef int p[1000] # Another C type
result = [] # A Python type
if kmax > 1000:
kmax = 1000
k = 0
n = 2
while k < kmax:
i = 0
while i < k and n % p[i] != 0:
i = i + 1
if i == k:
p[k] = n
k = k + 1
result.append(n)
n = n + 1
return result
In [1]: %load_ext Cython
In [2]: %%cython
...: def f(n):
...: a = 0
...: for i in range(n):
...: a += i
...: return a
...:
...: cpdef g(int n):
...: cdef int a = 0, i
...: for i in range(n):
...: a += i
...: return a
...:
In [3]: %timeit f(1000000)
42.7 ms ± 783 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)
In [4]: %timeit g(1000000)
74 µs ± 16.6 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
# which gives a 585 times improvement over the pure-python version
Cython compiling:
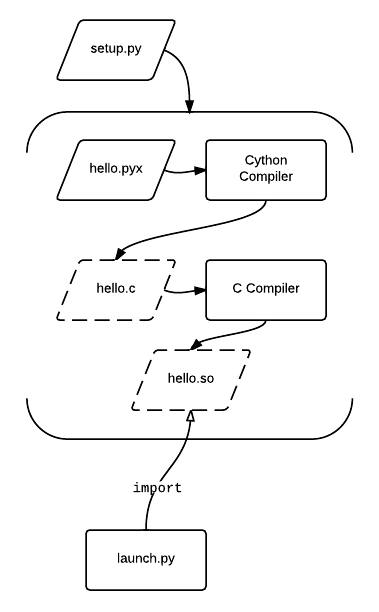
16.2.8. Numba¶
Numba gives you the power to speed up your applications with high performance functions written directly in Python. With a few annotations, array-oriented and math-heavy Python code can be just-in-time compiled to native machine instructions, similar in performance to C, C++ and Fortran, without having to switch languages or Python interpreters.
>>>
... from numba import jit, int32
...
...
... @jit(nogil=True)
... def do_something():
... pass
...
...
... @jit(int32(int32, int32))
... def add(x, y):
... return x + y
16.2.9. Dask¶
Dask natively scales Python. Dask provides advanced parallelism for analytics, enabling performance at scale for the tools you love.
Dask's schedulers scale to thousand-node clusters and its algorithms have been tested on some of the largest supercomputers in the world.
But you don't need a massive cluster to get started. Dask ships with schedulers designed for use on personal machines. Many people use Dask today to scale computations on their laptop, using multiple cores for computation and their disk for excess storage.
16.2.10. Find existing implementation¶
16.2.11. String Concatenation¶
How many string are there in a memory?:
>>> firstname = 'Mark'
>>> lastname = 'Watney'
>>>
>>> firstname + ' ' + lastname
'Mark Watney'
How many string are there in a memory?:
>>> firstname = 'Mark'
>>> lastname = 'Watney'
>>>
>>> f'{firstname} {lastname}'
'Mark Watney'
How many string are there in a memory?:
>>> firstname = 'Mark'
>>> lastname = 'Watney'
>>> age = 42
>>>
>>> 'Hello ' + firstname + ' ' + lastname + ' ' + str(age) + '!'
'Hello Mark Watney 42!'
How many string are there in a memory?:
>>> firstname = 'Mark'
>>> lastname = 'Watney'
>>> age = 42
>>>
>>> f'Hello {firstname} {lastname} {age}!'
'Hello Mark Watney 42!'
16.2.12. String Append¶
Use
list.append()instead ofstr + str:
Concatenates strings using + in a loop:
>>> DATA = ['Mark Watney', 'Melissa Lewis', 'Rick Martinez']
>>> result = '<table>'
>>>
>>> for element in DATA:
... result += f'<tr><td>{element}</td></tr>'
>>>
>>> result += '</table>'
>>> print(result)
<table><tr><td>Mark Watney</td></tr><tr><td>Melissa Lewis</td></tr><tr><td>Rick Martinez</td></tr></table>
Problem solved:
>>> DATA = ['Mark Watney', 'Melissa Lewis', 'Rick Martinez']
>>> result = ['<table>']
>>>
>>> for element in DATA:
... result.append(f'<tr><td>{element}</td></tr>')
>>>
>>> result.append('</table>')
>>> print(''.join(result))
<table><tr><td>Mark Watney</td></tr><tr><td>Melissa Lewis</td></tr><tr><td>Rick Martinez</td></tr></table>
16.2.13. Range between two float¶
There are indefinitely many values between two floats
>>> range(0, 1)
range(0, 1)
Note, that in Python following code will not execute, as of range() requires two integers. However similar code with numpy.arange() will work.
>>> range(0.0, 1.0)
0.000...000
0.000...001
0.000...002
0.000...003
16.2.14. Deque¶
collections.deque- Double ended Queue
16.2.15. Further Reading¶
16.2.16. References¶
16.2.17. Assignments¶
"""
* Assignment: Memoization
* Complexity: medium
* Lines of code: 5 lines
* Time: 13 min
English:
1. Create empty `dict` named `CACHE`
2. In the dictionary, we will store the results of calculating the function for the given parameters:
a. key: function argument
b. value: calculation result
3. Modify function `factorial_cache(n: int)`
4. Before running the function, check if the result has already been calculated:
a. if so, return data from `CACHE`
b. if not, calculate, update `CACHE`, and then return the value
5. Compare the speed of operation
6. Run doctests - all must succeed
Polish:
1. Stwórz pusty `dict` o nazwie `CACHE`
2. W słowniku będziemy przechowywali wyniki wyliczenia funkcji dla zadanych parametrów:
a. klucz: argument funkcji
b. wartość: wynik obliczeń
3. Zmodyfikuj funkcję `factorial_cache(n: int)`
4. Przed uruchomieniem funkcji, sprawdź czy wynik został już wcześniej obliczony:
a. jeżeli tak, to zwraca dane z `CACHE`
b. jeżeli nie, to oblicza, aktualizuje `CACHE`, a następnie zwraca wartość
5. Porównaj prędkość działania
6. Uruchom doctesty - wszystkie muszą się powieść
Tests:
TODO: Doctests
"""
from timeit import timeit
import sys
sys.setrecursionlimit(5000)
def factorial_cache(n: int) -> int:
...
# Do not modify anything below
def factorial_nocache(n: int) -> int:
if n == 0:
return 1
else:
return n * factorial_nocache(n - 1)
duration_cache = timeit(
stmt='factorial_cache(500); factorial_cache(400); factorial_cache(450); factorial_cache(350)',
globals=globals(),
number=10000,
)
duration_nocache = timeit(
stmt='factorial_nocache(500); factorial_nocache(400); factorial_nocache(450); factorial_nocache(350)',
globals=globals(),
number=10000
)
print(f'factorial_cache time: {round(duration_cache, 4)} seconds')
print(f'factorial_nocache time: {round(duration_nocache, 3)} seconds')
print(f'Cached solution is {round(duration_nocache / duration_cache, 1)} times faster')