4.1. Regex Syntax About¶
Also known as
Regular ExpressionsAlso known as
Regular ExprAlso known as
regexpAlso known as
regexAlso known as
rehttps://www.youtube.com/watch?v=BmF-gEYXWVM&list=PLv4THqSPE6meFeo_jNLgUVKkP40UstIQv&index=3
W3C HTML Email pattern:
r"^[a-zA-Z0-9.!#$%&'*+/=?^_`{|}~-]+@[a-zA-Z0-9-]+(?:\.[a-zA-Z0-9-]+)*$"
W3C HTML5 Standard [5] regexp for email field
>>> pattern = r"^[a-zA-Z0-9.!#$%&'*+/=?^_`{|}~-]+@[a-zA-Z0-9-]+(?:\.[a-zA-Z0-9-]+)*$"
4.1.1. SetUp¶
TEXT = 'Email from Mark Watney <mwatney@nasa.gov> received on: Sat, Jan 1st, 2000 at 12:00 AM'TEXT is short
TEXT has firstname and lastname
TEXT has date
TEXT has time
TEXT has punctuation (
,and.)TEXT has digits and numbers
TEXT has ordinals (th) - from st, nd, rd, th
TEXT has lowercase and uppercase letters
>>> import re
>>> TEXT = 'Email from Mark Watney <mwatney@nasa.gov> received on: Sat, Jan 1st, 2000 at 12:00 AM'
>>> JFK = """We choose to go to the moon.
... We choose to go to the moon in this decade and do the other things,
... not because they are easy, but because they are hard,
... because that goal will serve to organize and measure the best of our energies and skills,
... because that challenge is one that we are willing to accept,
... one we are unwilling to postpone,
... and one which we intend to win,
... and the others, too."""
>>> APOLLO = """Apollo 11 was the American spaceflight that first landed
... humans on the Moon. Commander (CDR) Neil Armstrong and lunar module
... pilot (LMP) Buzz Aldrin landed the Apollo Lunar Module (LM) Eagle on
... July 20th, 1969 at 20:17 UTC, and Armstrong became the first person
... to step (EVA) onto the Moon's surface (EVA) 6 hours 39 minutes later,
... on July 21st, 1969 at 02:56:15 UTC. Aldrin joined him 19 minutes later.
... They spent 2 hours 31 minutes exploring the site they had named Tranquility
... Base upon landing. Armstrong and Aldrin collected 47.5 pounds (21.5 kg)
... of lunar material to bring back to Earth as pilot Michael Collins (CMP)
... flew the Command Module (CM) Columbia in lunar orbit, and were on the
... Moon's surface for 21 hours 36 minutes before lifting off to rejoin
... Columbia."""
4.1.2. Syntax¶
Identifiers - what to find (single character)
Qualifiers - range to find (range)
Negation
Quantifiers - how many occurrences of preceding qualifier or identifier
Groups
Look Ahead and Look Behind
Flags
Extensions
[]- Qualifier{}- Quantifier()- Groups
4.1.3. Escape characters¶
Escape characters
\t- tab\r- carriage return\n- newline\r\n- newline (on Windows)\b- backspace\v- vertical space\f- form feed\x- hexadecimal\o- octal\u- Unicode entity 16-bit\U- Unicode entity 32-bit\\- backslash\'- apostrophe\"- double quote
>>> import string
>>>
>>>
>>> string.whitespace
' \t\n\r\x0b\x0c'
>>> print('hello\nworld')
hello
world
Linefeed means to advance downward to the next line; however, it has been repurposed and renamed. Used as "newline", it terminates lines (commonly confused with separating lines). This is commonly escaped as n, abbreviated LF or NL, and has ASCII value 10 or 0x0A. CRLF (but not CRNL) is used for the pair rn [4].
>>> print('hello\r\nworld')
hello
world
Carriage return means to return to the beginning of the current line without advancing downward. The name comes from a printer's carriage, as monitors were rare when the name was coined. This is commonly escaped as r, abbreviated CR, and has ASCII value 13 or 0x0D [4].
>>> print('hello\rworld')
world
The most common difference (and probably the only one worth worrying about) is lines end with CRLF on Windows, NL on Unix-likes, and CR on older Macs (the situation has changed with OS X to be like Unix). Note the shift in meaning from LF to NL, for the exact same character, gives the differences between Windows and Unix. (Windows is, of course, newer than Unix, so it didn't adopt this semantic shift. That probably came from the Apple II using CR. CR was common on other 8-bit systems, too, like the Commodore and Tandy. ASCII wasn't universal on these systems: Commodore used PETSCII, which had LF at 0x8d (!). Atari had no LF character at all. For whatever reason, CR = 0x0d was more-or-less standard. Many text editors can read files in any of these three formats and convert between them, but not all utilities can [4].
>>> print('hello\bworld')
hellworld
b is a nondestructive backspace. It moves the cursor backward, but doesn't erase what's there. Then following output overwrites the previous.
>>> print('hello\sworld')
hello\sworld
>>> print('hello\tworld')
hello world
Form feed means advance downward to the next "page". It was commonly used as page separators, but now is also used as section separators. (It's uncommonly used in source code to divide logically independent functions or groups of functions.) Text editors can use this character when you "insert a page break". This is commonly escaped as f, abbreviated FF, and has ASCII value 12 or 0x0C [4].
>>> print('hello\fworld')
hello
world
Form feed is a bit more interesting (even though less commonly used directly), and with the usual definition of page separator, it can only come between lines (e.g. after the newline sequence of NL, CRLF, or CR) or at the start or end of the file [4].
Vertical tab was used to speed up printer vertical movement. Some printers used special tab belts with various tab spots. This helped align content on forms. VT to header space, fill in header, VT to body area, fill in lines, VT to form footer. Generally it was coded in the program as a character constant. From the keyboard, it would be CTRL-K. It is hardly used any more. Most forms are generated in a printer control language like postscript [2].
>>> print('hello\vworld')
hello
world
The above output appears to result in the default vertical size being one line. This could be used to do line feed without a carriage return on devices with convert linefeed to carriage-return + linefeed [2].
Microsoft Word uses VT as a line separator in order to distinguish it from the normal new line function, which is used as a paragraph separator [3].
4.1.4. String Modifiers¶
>>> text = f'hello'
>>> text = b'hello'
>>> text = u'hello'
>>> text = r'hello'
>>> text = F'hello'
>>> text = B'hello'
>>> text = U'hello'
>>> text = R'hello'
>>> text = 'cześć'
>>> text.encode()
b'cze\xc5\x9b\xc4\x87'
>>>
>>> text = b'cze\xc5\x9b\xc4\x87'
>>> text.decode()
'cześć'
>>> print('hello world')
hello world
>>>
>>>
>>> print('hello\tworld')
hello world
>>>
>>> print('hello\nworld')
hello
world
>>>
>>>
>>> print(r'hello\nworld')
hello\nworld
>>>
>>> print(r'hello\tworld')
hello\tworld
4.1.5. Raw Strings¶
Recap information about raw strings
r'...'Since Python 3.12
r-stringis required https://docs.python.org/dev/whatsnew/3.12.html#other-language-changes
Since Python 3.12 gh-98401:
A backslash-character pair that is not a valid escape sequence now generates a
SyntaxWarning, instead ofDeprecationWarning. For example,re.compile("\d+")now emits aSyntaxWarning("d" is an invalid escape sequence), use raw strings for regular expression:re.compile(r"\d+"). In a future Python version,SyntaxErrorwill eventually be raised, instead ofSyntaxWarning.
>>> print('hello\nworld')
hello
world
>>> print('hello\\nworld')
hello\nworld
>>> print(r'hello\nworld')
hello\nworld
Example:
>>> print('\btodo\b')
todo
>>>
>>> print(r'\btodo\b')
\btodo\b
4.1.6. ASCII vs Unicode¶
re.UNICODEre.ASCIIASCII for letters in latin alphabet
UNICODE includes diacritics and accent characters (ąśćłóźć, etc.)
>>> import string
>>>
>>>
>>> string.ascii_lowercase
'abcdefghijklmnopqrstuvwxyz'
>>>
>>> string.ascii_uppercase
'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
>>>
>>> string.ascii_letters
'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
>>> import unicodedata
>>>
>>>
>>> unicodedata.name('a')
'LATIN SMALL LETTER A'
>>>
>>> unicodedata.name('ą')
'LATIN SMALL LETTER A WITH OGONEK'
>>>
>>> unicodedata.name('ś')
'LATIN SMALL LETTER S WITH ACUTE'
>>>
>>> unicodedata.name('ł')
'LATIN SMALL LETTER L WITH STROKE'
>>>
>>> unicodedata.name('ż')
'LATIN SMALL LETTER Z WITH DOT ABOVE'
>>>
>>> print('\U0001F680')
🚀
>>> import unicodedata
>>>
>>>
>>> a = '\U0001F9D1' # 🧑
>>> b = '\U0000200D' # ''
>>> c = '\U0001F680' # 🚀
>>>
>>> astronaut = a + b + c
>>> print(astronaut)
🧑🚀
>>>
>>> unicodedata.name(a)
'ADULT'
>>>
>>> unicodedata.name(b)
'ZERO WIDTH JOINER'
>>>
>>> unicodedata.name(c)
'ROCKET'
>>>
>>> unicodedata.name(astronaut)
Traceback (most recent call last):
TypeError: name() argument 1 must be a unicode character, not str
4.1.7. Digit, Hexadecimal, Octal¶
>>> import string
>>>
>>>
>>> string.digits
'0123456789'
>>>
>>> string.hexdigits
'0123456789abcdefABCDEF'
>>>
>>> string.octdigits
'01234567'
4.1.8. Punctuation¶
>>> import string
>>>
>>>
>>> string.punctuation
'!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~'
>>>
>>> string.printable
'0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~ \t\n\r\x0b\x0c'
4.1.9. Visualization¶
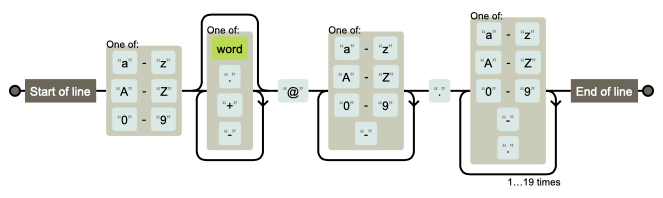
Figure 4.1. Visualization for pattern r'^[a-zA-Z0-9][\w.+-]*@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]{2,20}$' [1]¶
4.1.10. Further Reading¶
https://www.youtube.com/watch?v=BmF-gEYXWVM&list=PLv4THqSPE6meFeo_jNLgUVKkP40UstIQv&index=3
Kinsley, Harrison "Sentdex". Python 3 Programming Tutorial - Regular Expressions / Regex with re. Year: 2014. Retrieved: 2021-04-11. URL: https://www.youtube.com/watch?v=sZyAn2TW7GY
https://www.rexegg.com/regex-trick-conditional-replacement.html