12.5. File Encoding¶
utf-8- a.k.a. Unicode - international standard (should be always used!)iso-8859-1- ISO standard for Western Europe and USAiso-8859-2- ISO standard for Central Europe (including Poland)cp1250orwindows-1250- Central European encoding on Windowscp1251orwindows-1251- Eastern European encoding on Windowscp1252orwindows-1252- Western European encoding on WindowsASCII- ASCII characters onlySince Windows 10 version 1903, UTF-8 is default encoding for Notepad!
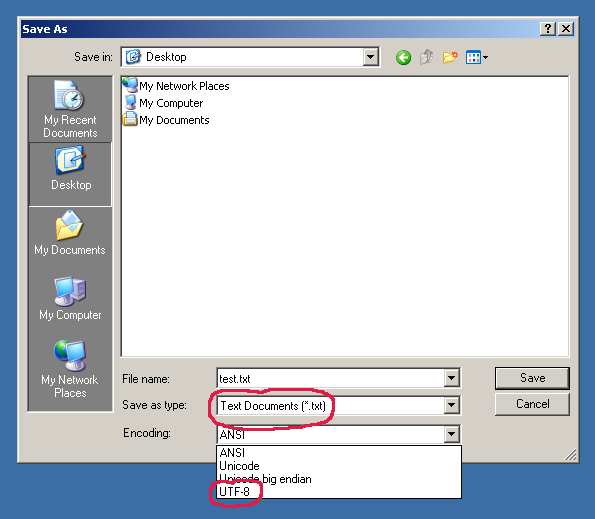
Figure 12.1. Windows 2000 Notepad "Save As" window with possibility to select encoding. UTF-8 is not selected by default... Source: [3]¶
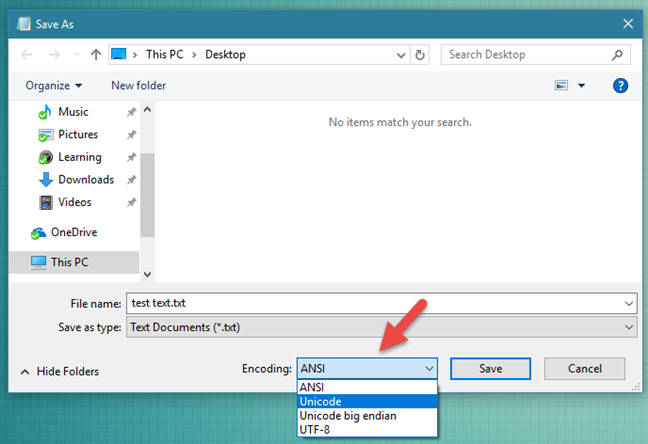
Figure 12.2. Windows 10 Notepad "Save As" window with possibility to select encoding. Since Windows 10.1903 (May 2019) notepad writes files in UTF-8 by default! Source: [4] [5]¶
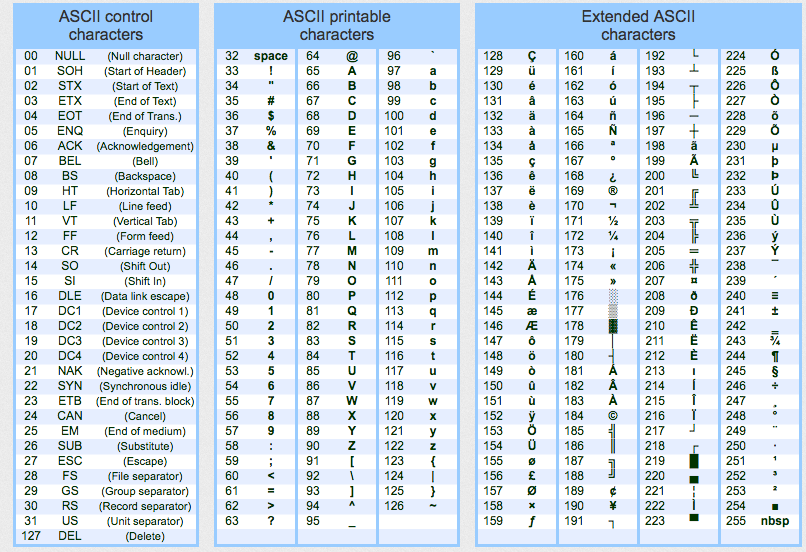
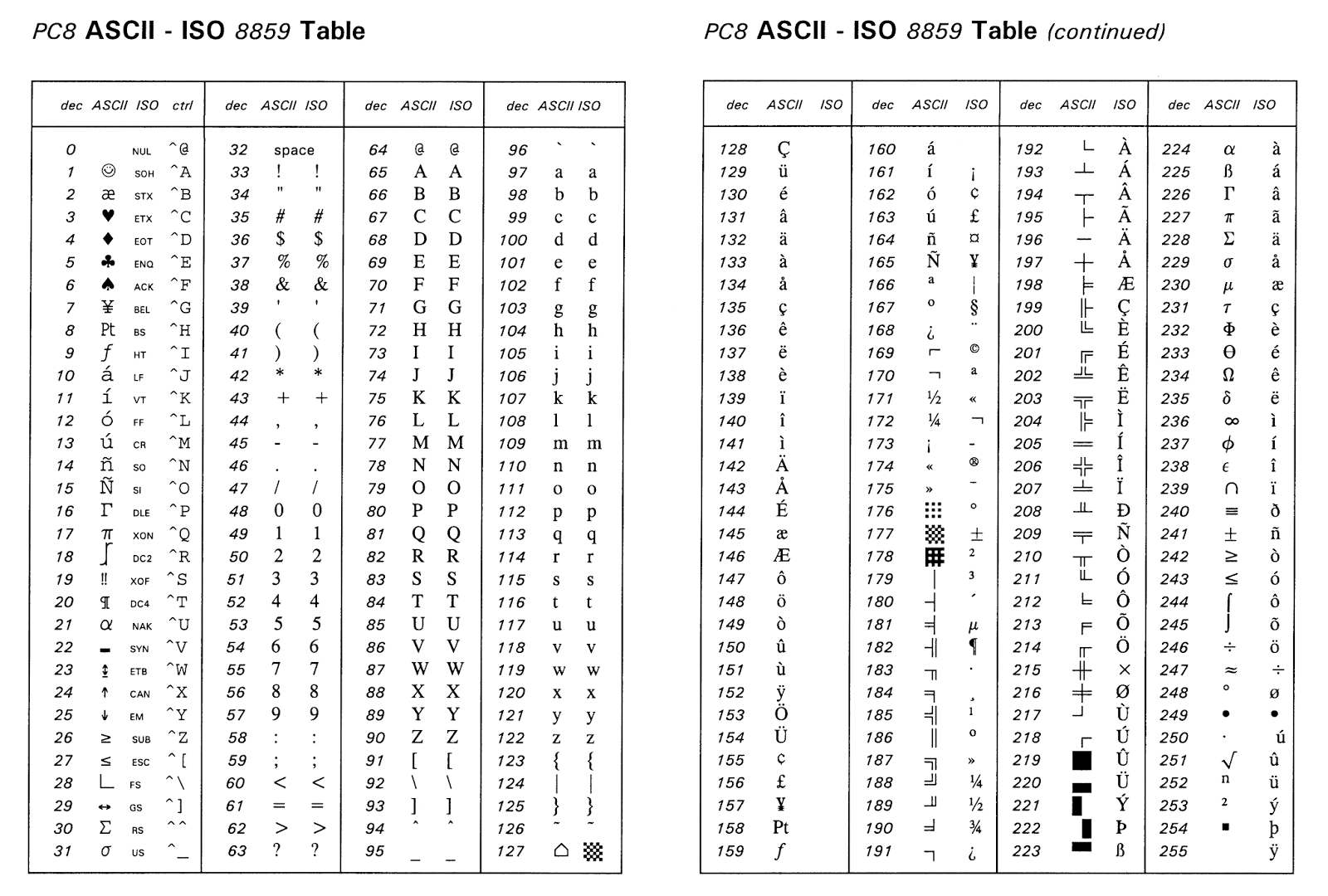

12.5.1. Str vs Bytes¶
That was a big change in Python 3
In Python 2, str was bytes
In Python 3, str is unicode (UTF-8)
>>> text = 'Księżyc'
>>> text
'Księżyc'
>>> text = b'Księżyc'
Traceback (most recent call last):
SyntaxError: bytes can only contain ASCII literal characters
Default encoding is UTF-8. Encoding names are case insensitive.
cp1250 and windows-1250 are aliases the same codec:
>>> text = 'Księżyc'
>>>
>>> text.encode()
b'Ksi\xc4\x99\xc5\xbcyc'
>>> text.encode('utf-8')
b'Ksi\xc4\x99\xc5\xbcyc'
>>> text.encode('iso-8859-2')
b'Ksi\xea\xbfyc'
>>> text.encode('cp1250')
b'Ksi\xea\xbfyc'
>>> text.encode('windows-1250')
b'Ksi\xea\xbfyc'
Note the length change while encoding:
>>> text = 'Księżyc'
>>> text
'Księżyc'
>>> len(text)
7
>>> text = 'Księżyc'.encode()
>>> text
b'Ksi\xc4\x99\xc5\xbcyc'
>>> len(text)
9
Note also, that those characters produce longer output:
>>> 'ó'.encode()
b'\xc3\xb3'
But despite being several "characters" long, the length is different:
>>> len(b'\xc3\xb3')
2
Here's the output of all Polish diacritics (accented characters) with their encoding:
>>> 'ą'.encode()
b'\xc4\x85'
>>> 'ć'.encode()
b'\xc4\x87'
>>> 'ę'.encode()
b'\xc4\x99'
>>> 'ł'.encode()
b'\xc5\x82'
>>> 'ń'.encode()
b'\xc5\x84'
>>> 'ó'.encode()
b'\xc3\xb3'
>>> 'ś'.encode()
b'\xc5\x9b'
>>> 'ż'.encode()
b'\xc5\xbc'
>>> 'ź'.encode()
b'\xc5\xba'
Note also a different way of iterating over bytes:
>>> text = 'Księżyc'
>>>
>>> for character in text:
... print(character)
K
s
i
ę
ż
y
c
>>>
>>> for character in text.encode():
... print(character)
75
115
105
196
153
197
188
121
99
12.5.2. UTF-8¶
>>> FILE = r'/tmp/myfile.txt'
>>>
>>> with open(FILE, mode='w', encoding='utf-8') as file:
... file.write('José Jiménez')
12
>>>
>>> with open(FILE, encoding='utf-8') as file:
... print(file.read())
José Jiménez
12.5.3. Unicode Encode Error¶
>>> FILE = r'/tmp/myfile.txt'
>>>
>>> with open(FILE, mode='w', encoding='cp1250') as file:
... file.write('José Jiménez')
12
12.5.4. Unicode Decode Error¶
>>> FILE = r'/tmp/myfile.txt'
>>>
>>> with open(FILE, mode='w', encoding='utf-8') as file:
... file.write('José Jiménez')
12
>>>
>>> with open(FILE, encoding='cp1250') as file:
... print(file.read())
José Jiménez
12.5.5. Escape Characters¶
\r\n- is used on windows\n- is used everywhere elseMore information in Builtin Printing
Learn more at https://en.wikipedia.org/wiki/List_of_Unicode_characters

Figure 12.9. Why we have '\r\n' on Windows?¶

Frequently used escape characters:
\n- New line (ENTER)
\t- Horizontal Tab (TAB)
\'- Single quote'(escape in single quoted strings)
\"- Double quote"(escape in double quoted strings)
\\- Backslash\(to indicate, that this is not escape char)
Less frequently used escape characters:
\a- Bell (BEL)
\b- Backspace (BS)
\f- New page (FF - Form Feed)
\v- Vertical Tab (VT)
\uF680- Character with 16-bit (2 bytes) hex valueF680
\U0001F680- Character with 32-bit (4 bytes) hex value0001F680
\o755- ASCII character with octal value755
\x1F680- ASCII character with hex value1F680
Emoticons:
>>> print('\U0001F680')
🚀
>>> a = '\U0001F9D1' # 🧑
>>> b = '\U0000200D' # ''
>>> c = '\U0001F680' # 🚀
>>>
>>> astronaut = a + b + c
>>> print(astronaut)
🧑🚀