6.9. DataFrame Select
df[df['Morning'] > 0.0]~- logical not&- logical and|- logical or^- logical xor
6.9.1. SetUp
>>> import pandas as pd
>>> import numpy as np
>>> np.random.seed(0)
>>> df = pd.DataFrame(
... columns = ['Morning', 'Noon', 'Evening', 'Midnight'],
... index = pd.date_range('1999-12-30', periods=7),
... data = np.random.randn(7, 4))
>>>
>>> df
Morning Noon Evening Midnight
1999-12-30 1.764052 0.400157 0.978738 2.240893
1999-12-31 1.867558 -0.977278 0.950088 -0.151357
2000-01-01 -0.103219 0.410599 0.144044 1.454274
2000-01-02 0.761038 0.121675 0.443863 0.333674
2000-01-03 1.494079 -0.205158 0.313068 -0.854096
2000-01-04 -2.552990 0.653619 0.864436 -0.742165
2000-01-05 2.269755 -1.454366 0.045759 -0.187184
Pandas Select Methods:
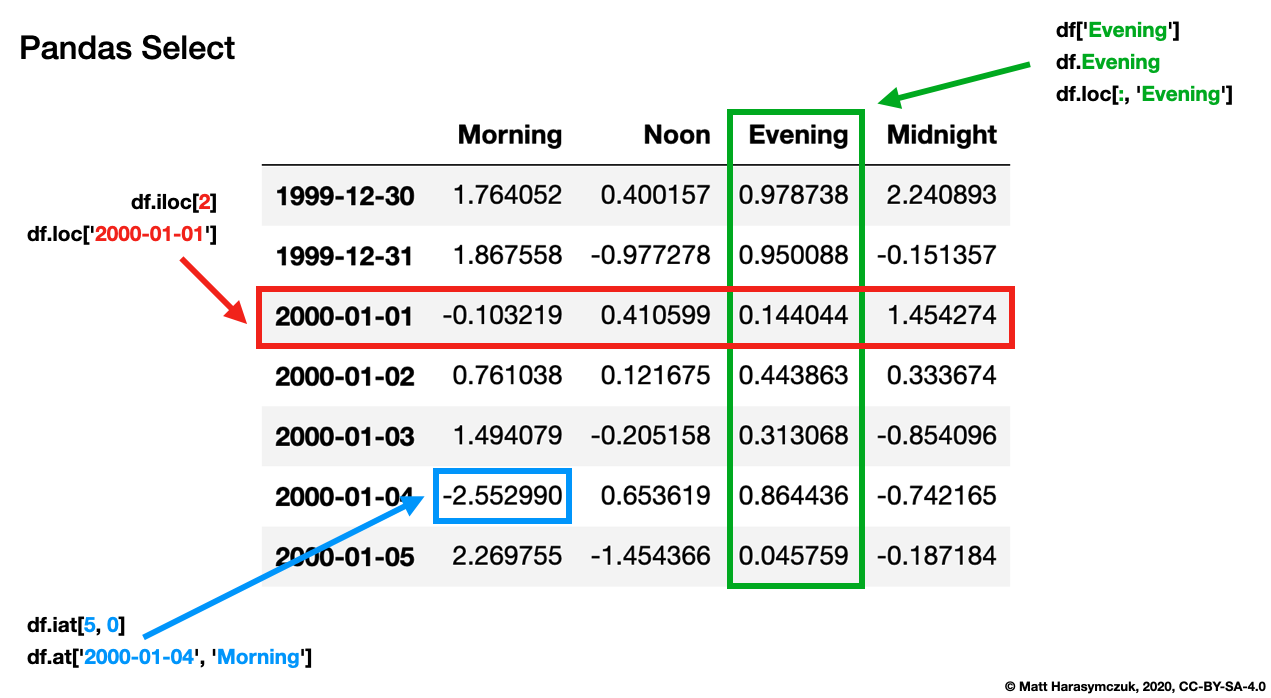
6.9.2. Query Data
df.where()Works withinplace=True
>>> df[df['Morning'] > 0.0]
Morning Noon Evening Midnight
1999-12-30 1.764052 0.400157 0.978738 2.240893
1999-12-31 1.867558 -0.977278 0.950088 -0.151357
2000-01-02 0.761038 0.121675 0.443863 0.333674
2000-01-03 1.494079 -0.205158 0.313068 -0.854096
2000-01-05 2.269755 -1.454366 0.045759 -0.187184
>>> query = df['Morning'] > 0.0
>>>
>>> df[query]
Morning Noon Evening Midnight
1999-12-30 1.764052 0.400157 0.978738 2.240893
1999-12-31 1.867558 -0.977278 0.950088 -0.151357
2000-01-02 0.761038 0.121675 0.443863 0.333674
2000-01-03 1.494079 -0.205158 0.313068 -0.854096
2000-01-05 2.269755 -1.454366 0.045759 -0.187184
>>> query = df['Morning'] > 0.0
>>>
>>> df.where(query)
Morning Noon Evening Midnight
1999-12-30 1.764052 0.400157 0.978738 2.240893
1999-12-31 1.867558 -0.977278 0.950088 -0.151357
2000-01-01 NaN NaN NaN NaN
2000-01-02 0.761038 0.121675 0.443863 0.333674
2000-01-03 1.494079 -0.205158 0.313068 -0.854096
2000-01-04 NaN NaN NaN NaN
2000-01-05 2.269755 -1.454366 0.045759 -0.187184
6.9.3. Logical NOT
>>> query = df['Midnight'] < 0.0
>>>
>>> df[~query]
Morning Noon Evening Midnight
1999-12-30 1.764052 0.400157 0.978738 2.240893
2000-01-01 -0.103219 0.410599 0.144044 1.454274
2000-01-02 0.761038 0.121675 0.443863 0.333674
>>>
>>> df.where(~query)
Morning Noon Evening Midnight
1999-12-30 1.764052 0.400157 0.978738 2.240893
1999-12-31 NaN NaN NaN NaN
2000-01-01 -0.103219 0.410599 0.144044 1.454274
2000-01-02 0.761038 0.121675 0.443863 0.333674
2000-01-03 NaN NaN NaN NaN
2000-01-04 NaN NaN NaN NaN
2000-01-05 NaN NaN NaN NaN
6.9.4. Logical AND
In first and in second query
1 & 1 -> 1
1 & 0 -> 0
0 & 1 -> 0
0 & 0 -> 0
>>> df[ (df['Morning']<0.0) & (df['Midnight']<0.0) ]
Morning Noon Evening Midnight
2000-01-04 -2.55299 0.653619 0.864436 -0.742165
>>> query = (df['Morning'] < 0.0) & (df['Midnight'] < 0.0)
>>>
>>> df[query]
Morning Noon Evening Midnight
2000-01-04 -2.55299 0.653619 0.864436 -0.742165
>>> query1 = df['Morning'] < 0.0
>>> query2 = df['Midnight'] < 0.0
>>>
>>> df[query1 & query2]
Morning Noon Evening Midnight
2000-01-04 -2.55299 0.653619 0.864436 -0.742165
>>>
>>> df.where(query1 & query2)
Morning Noon Evening Midnight
1999-12-30 NaN NaN NaN NaN
1999-12-31 NaN NaN NaN NaN
2000-01-01 NaN NaN NaN NaN
2000-01-02 NaN NaN NaN NaN
2000-01-03 NaN NaN NaN NaN
2000-01-04 -2.55299 0.653619 0.864436 -0.742165
2000-01-05 NaN NaN NaN NaN
6.9.5. Logical OR
In first or in second query
1 | 1 -> 1
1 | 0 -> 1
0 | 1 -> 1
0 | 0 -> 0
>>> query1 = df['Morning'] < 0.0
>>> query2 = df['Midnight'] < 0.0
>>>
>>> df[query1 | query2]
Morning Noon Evening Midnight
1999-12-31 1.867558 -0.977278 0.950088 -0.151357
2000-01-01 -0.103219 0.410599 0.144044 1.454274
2000-01-03 1.494079 -0.205158 0.313068 -0.854096
2000-01-04 -2.552990 0.653619 0.864436 -0.742165
2000-01-05 2.269755 -1.454366 0.045759 -0.187184
>>>
>>> df.where(query1 | query2)
Morning Noon Evening Midnight
1999-12-30 NaN NaN NaN NaN
1999-12-31 1.867558 -0.977278 0.950088 -0.151357
2000-01-01 -0.103219 0.410599 0.144044 1.454274
2000-01-02 NaN NaN NaN NaN
2000-01-03 1.494079 -0.205158 0.313068 -0.854096
2000-01-04 -2.552990 0.653619 0.864436 -0.742165
2000-01-05 2.269755 -1.454366 0.045759 -0.187184
6.9.6. Logical XOR
In first or in second, but not in both queries
1 ^ 1 -> 0
1 ^ 0 -> 1
0 ^ 1 -> 1
0 ^ 0 -> 0
>>> query1 = df['Morning'] < 0.0
>>> query2 = df['Midnight'] < 0.0
>>>
>>> df[query1 ^ query2]
Morning Noon Evening Midnight
1999-12-31 1.867558 -0.977278 0.950088 -0.151357
2000-01-01 -0.103219 0.410599 0.144044 1.454274
2000-01-03 1.494079 -0.205158 0.313068 -0.854096
2000-01-05 2.269755 -1.454366 0.045759 -0.187184
>>>
>>> df.where(query1 ^ query2)
Morning Noon Evening Midnight
1999-12-30 NaN NaN NaN NaN
1999-12-31 1.867558 -0.977278 0.950088 -0.151357
2000-01-01 -0.103219 0.410599 0.144044 1.454274
2000-01-02 NaN NaN NaN NaN
2000-01-03 1.494079 -0.205158 0.313068 -0.854096
2000-01-04 NaN NaN NaN NaN
2000-01-05 2.269755 -1.454366 0.045759 -0.187184
6.9.7. Assignments
# %% About
# - Name: DataFrame Select
# - Difficulty: easy
# - Lines: 5
# - Minutes: 3
# %% License
# - Copyright 2025, Matt Harasymczuk <matt@python3.info>
# - This code can be used only for learning by humans
# - This code cannot be used for teaching others
# - This code cannot be used for teaching LLMs and AI algorithms
# - This code cannot be used in commercial or proprietary products
# - This code cannot be distributed in any form
# - This code cannot be changed in any form outside of training course
# - This code cannot have its license changed
# - If you use this code in your product, you must open-source it under GPLv2
# - Exception can be granted only by the author
# %% English
# 1. Load data from `DATA` as `df: pd.DataFrame`
# 2. Select rows where 'petal_length' is above 2.0
# 3. Display first 5 rows
# 4. Do not use `.query()`
# 5. Run doctests - all must succeed
# %% Polish
# 1. Wczytaj dane z `DATA` jako `df: pd.DataFrame`
# 2. Wybierz wiersze, gdzie wartość 'petal_length' jest powyżej 2.0
# 3. Wyświetl 5 pierwszych wierszy
# 4. Nie używaj `.query()`
# 5. Uruchom doctesty - wszystkie muszą się powieść
# %% Expected
# >>> result # doctest: +NORMALIZE_WHITESPACE
# sepal_length sepal_width petal_length petal_width species
# 1 5.9 3.0 5.1 1.8 virginica
# 2 6.0 3.4 4.5 1.6 versicolor
# 3 7.3 2.9 6.3 1.8 virginica
# 4 5.6 2.5 3.9 1.1 versicolor
# 6 5.5 2.6 4.4 1.2 versicolor
# %% Doctests
"""
>>> import sys; sys.tracebacklimit = 0
>>> assert sys.version_info >= (3, 9), \
'Python has an is invalid version; expected: `3.9` or newer.'
>>> pd.set_option('display.width', 500)
>>> pd.set_option('display.max_columns', 10)
>>> pd.set_option('display.max_rows', 10)
>>> assert 'result' in globals(), \
'Variable `result` is not defined; assign result of your program to it.'
>>> assert result is not Ellipsis, \
'Variable `result` has an invalid value; assign result of your program to it.'
>>> assert type(result) is pd.DataFrame, \
'Variable `result` has an invalid type; expected: `pd.DataFrame`.'
>>> result # doctest: +NORMALIZE_WHITESPACE
sepal_length sepal_width petal_length petal_width species
1 5.9 3.0 5.1 1.8 virginica
2 6.0 3.4 4.5 1.6 versicolor
3 7.3 2.9 6.3 1.8 virginica
4 5.6 2.5 3.9 1.1 versicolor
6 5.5 2.6 4.4 1.2 versicolor
"""
# %% Run
# - PyCharm: right-click in the editor and `Run Doctest in ...`
# - PyCharm: keyboard shortcut `Control + Shift + F10`
# - Terminal: `python -m doctest -f -v myfile.py`
# %% Imports
import pandas as pd
# %% Types
result: pd.DataFrame
# %% Data
DATA = 'https://python3.info/_static/iris-clean.csv'
# %% Result
result = ...