5.18. Series Statistics
5.18.1. SetUp
>>> import pandas as pd
>>> import numpy as np
>>>
>>>
>>> s = pd.Series(
... data = [1.0, 2.0, 3.0, np.nan, 5.0],
... index = ['a', 'b', 'c', 'd', 'e'])
>>>
>>> s
a 1.0
b 2.0
c 3.0
d NaN
e 5.0
dtype: float64
5.18.2. Count
Series.count()- Number of non-null observationsSeries.nunique()- Number of unique valuesSeries.value_counts()- Frequency of unique valuesSeries.size- Number of elementslen(Series)- Number of elements
>>> len(s)
5
>>> s.size
5
>>> s.count()
np.int64(4)
>>> s.nunique()
4
>>> s.value_counts()
1.0 1
2.0 1
3.0 1
5.0 1
Name: count, dtype: int64
5.18.3. Sum
Series.sum()- Sum of valuesSeries.cumsum()- Cumulative sum
>>> s.sum()
np.float64(11.0)
>>> s.cumsum()
a 1.0
b 3.0
c 6.0
d NaN
e 11.0
dtype: float64
5.18.4. Product
Series.prod()- Product of valuesSeries.cumprod()- Cumulative product
>>> s.prod()
np.float64(30.0)
>>> s.cumprod()
a 1.0
b 2.0
c 6.0
d NaN
e 30.0
dtype: float64
5.18.5. Extremes
Series.min()- Minimum valueSeries.idxmin()- Index of minimum value (Float, Int, Object, Datetime, Index)Series.argmin()- Range index of minimum valueSeries.cummin()- Cumulative minimumSeries.max()- Maximum valueSeries.idxmax()- Index of maximum value (Float, Int, Object, Datetime, Index)Series.argmax()- Range index of maximum valueSeries.cummax()- Cumulative maximum
Minimum, index of minimum and cumulative minimum:
>>> s.min()
np.float64(1.0)
>>> s.idxmin()
'a'
>>> s.argmin()
np.int64(0)
>>> s.cummin()
a 1.0
b 1.0
c 1.0
d NaN
e 1.0
dtype: float64
Maximum, index of maximum and cumulative maximum:
>>> s.max()
np.float64(5.0)
>>> s.idxmax()
'e'
>>> s.argmax()
np.int64(4)
>>> s.cummax()
a 1.0
b 2.0
c 3.0
d NaN
e 5.0
dtype: float64
5.18.6. Average
Series.mean()- Arithmetic mean of valuesSeries.median()- Median of valuesSeries.mode()- Mode of valuesSeries.rolling(window=2).mean()- Rolling average
Arithmetic mean of values:
>>> s.mean()
np.float64(2.75)
Arithmetic median of values:
>>> s.median()
np.float64(2.5)
Mode:
>>> s.mode()
0 1.0
1 2.0
2 3.0
3 5.0
dtype: float64
Rolling Average:
>>> s.rolling(window=2).mean()
a NaN
b 1.5
c 2.5
d NaN
e NaN
dtype: float64
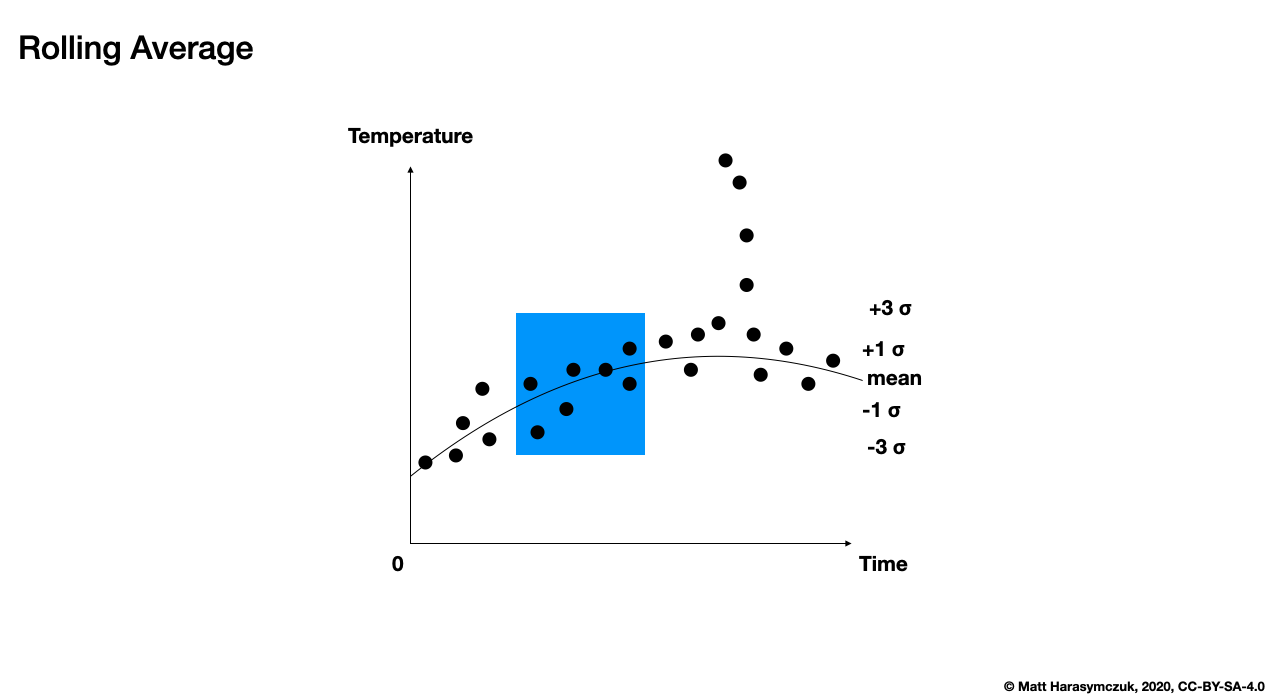
Figure 5.11. Rolling Average
5.18.7. Distribution
Series.abs()- Absolute valueSeries.std()- Standard deviationSeries.sem()- Standard Error of the Mean (SEM)Series.skew()- Skewness (3rd moment)Series.kurt()- Kurtosis (4th moment)Series.quantile()- Sample quantile (value at %)Series.var()- VarianceSeries.corr()- Correlation Coefficient
Absolute value:
>>> s.abs()
a 1.0
b 2.0
c 3.0
d NaN
e 5.0
dtype: float64
Standard deviation:
>>> s.std()
np.float64(1.707825127659933)
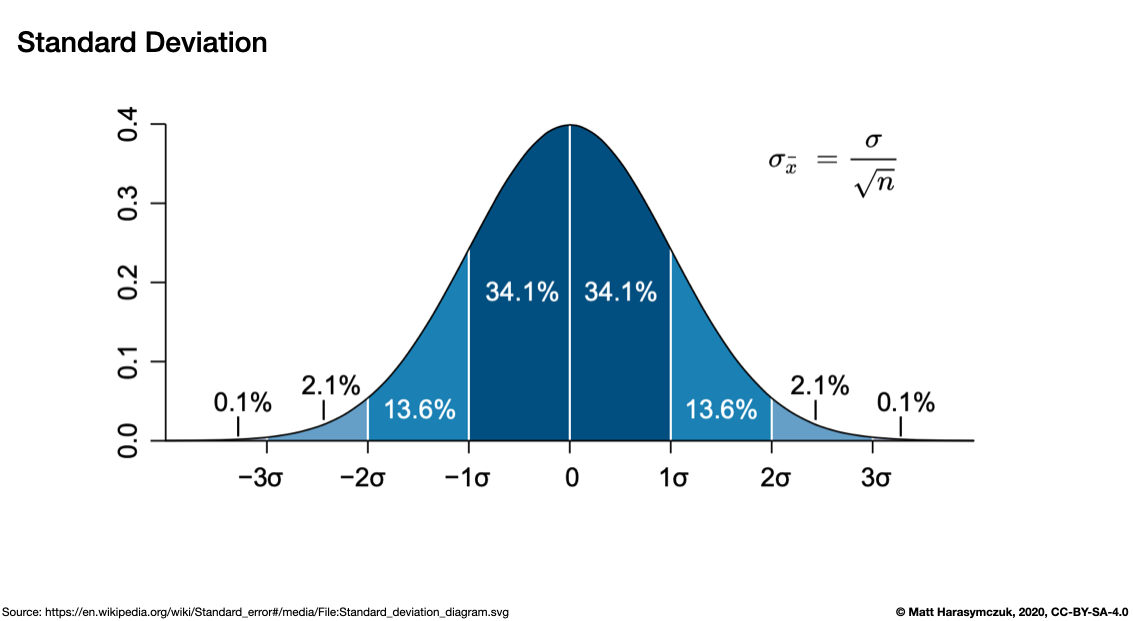
Figure 5.12. Standard Deviation
Standard Error of the Mean (SEM):
>>> s.sem()
np.float64(0.8539125638299665)
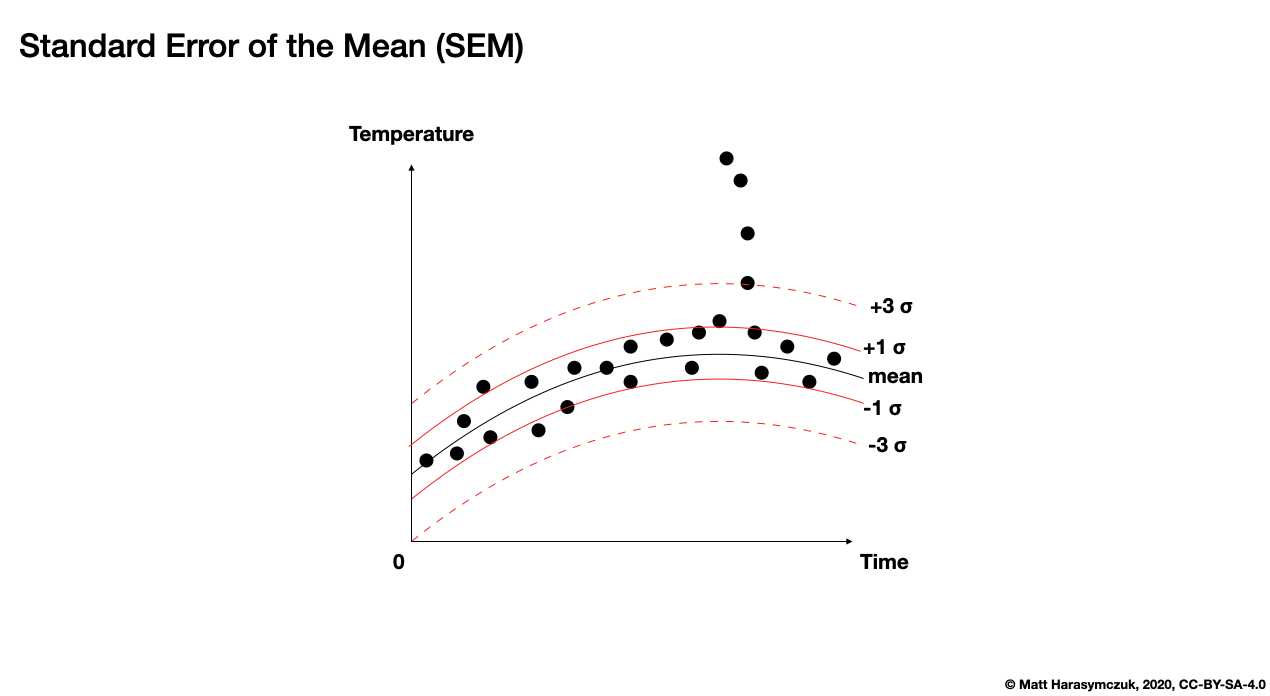
Figure 5.13. Standard Error of the Mean (SEM)
Skewness (3rd moment):
>>> s.skew()
np.float64(0.7528371991317256)
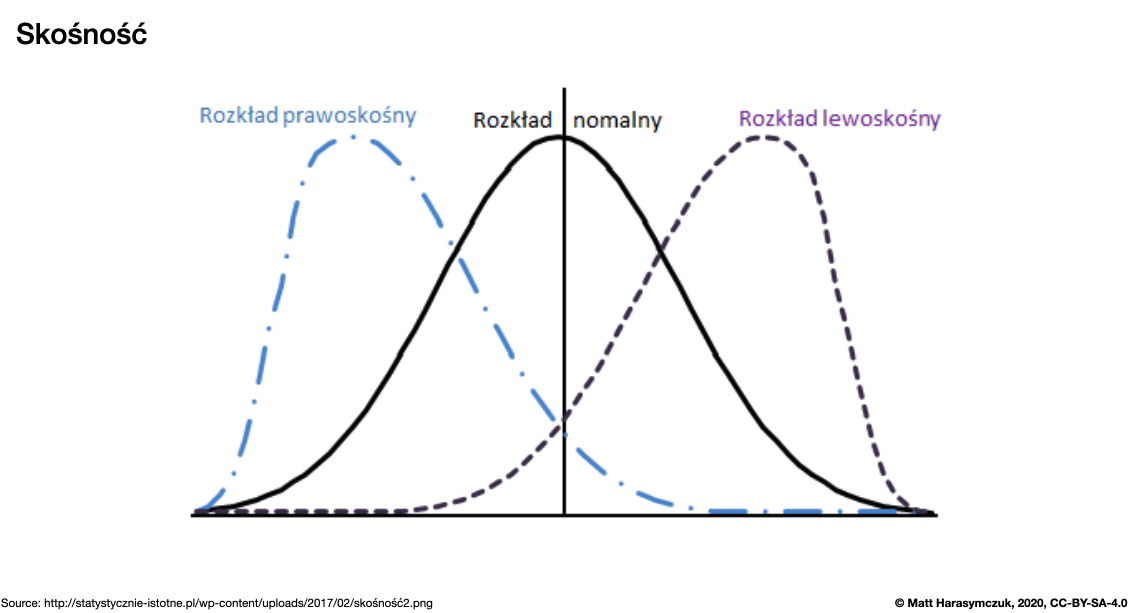
Figure 5.14. Skewness
Kurtosis (4th moment):
>>> s.kurt()
np.float64(0.3428571428571434)
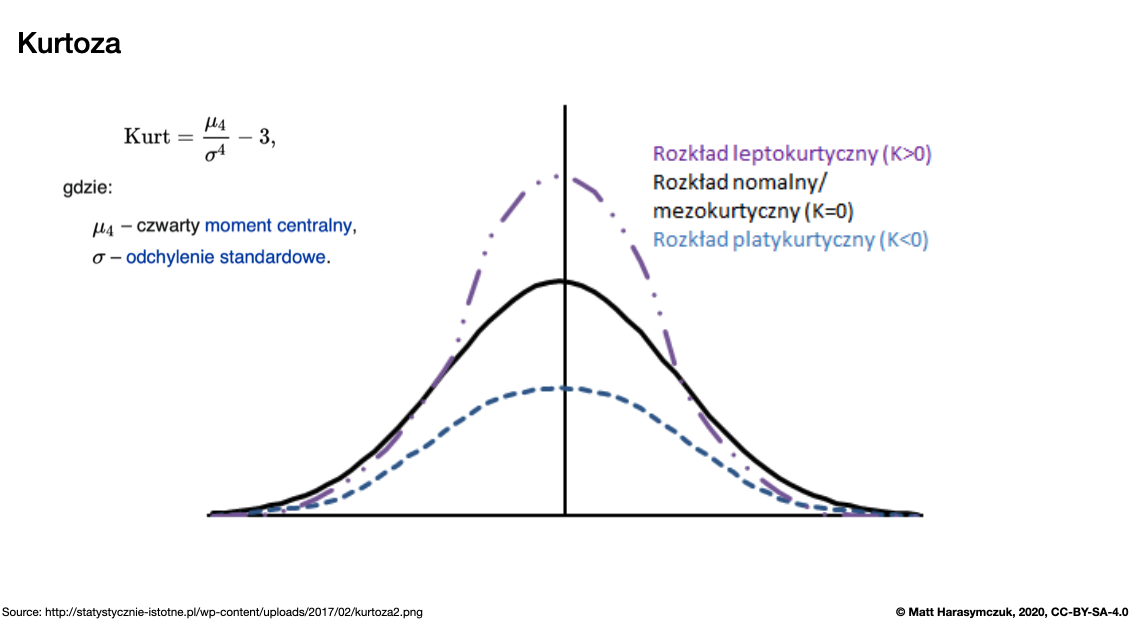
Figure 5.15. Kurtosis
Sample quantile (value at %). Quantile also known as Percentile:
>>> s.quantile(.3)
np.float64(1.9)
>>> s.quantile([.25, .5, .75])
0.25 1.75
0.50 2.50
0.75 3.50
dtype: float64
Variance:
>>> s.var()
np.float64(2.9166666666666665)
Correlation Coefficient:
>>> s.corr(s)
np.float64(1.0)
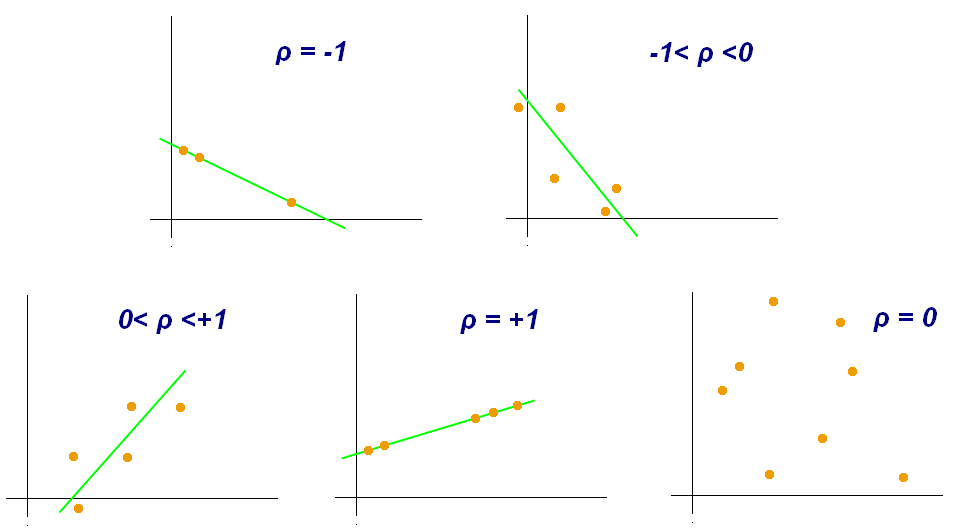
Figure 5.16. Correlation Coefficient
5.18.8. Describe
Series.describe()- Summary statistics
>>> s.describe()
count 4.000000
mean 2.750000
std 1.707825
min 1.000000
25% 1.750000
50% 2.500000
75% 3.500000
max 5.000000
dtype: float64