2.7. Features
2.7.1. Czym są features?
Attribute is also known as field, variable or feature.
A quantity describing an instance. An attribute has a domain defined by the attribute type, which denotes the values that can be taken by an attribute. The following domain types are common:
- Categorical:
A finite number of discrete values. The type nominal denotes that there is no ordering between the values, such as last names and colors. The type ordinal denotes that there is an ordering, such as in an attribute taking on the values low, medium, or high.
- Continuous (quantitative):
Commonly, subset of real numbers, where there is a measurable difference between the possible values. Integers are usually treated as continuous in practical problems.
A feature is the specification of an attribute and its value. For example, color is an attribute. "Color is blue" is a feature of an example. Many transformations to the attribute set leave the feature set unchanged (for example, regrouping attribute values or transforming multi-valued attributes to binary attributes). Some authors use feature as a synonym for attribute (e.g., in feature-subset selection).
2.7.2. Przykład praktyczny
Jak odróżnić jabłko od pomarańczy?
ilość pikseli pomarańczowych i ich stosunek do zielonych/czerwonych
co z czarno białymi zdjęciami?
co ze zdjęciami bez jabłek i pomarańczy

Figure 2.44. Apple vs. Oranges classification using orange and green pixel count.
def detect_colors(image):
# lots of code
def detect_edges(image):
# lots of code
def analyze_shapes(image):
# lots of code
def guess_texture(image):
# lots of code
def define_fruit(image):
# lots of code
def handle_probability(image):
# lots of code
Weight |
Texture |
Label |
|---|---|---|
170g |
Bumpy |
Orange |
150g |
Bumpy |
Orange |
140g |
Smooth |
Apple |
130g |
Smooth |
Apple |
Training Data table contains features and labels
# Input to the classifier
features = [
[170, 'bumpy'],
[150, 'bumpy'],
[140, 'smooth'],
[130, 'smooth'],
]
# Output that we want from classifier
labels = ['orange', 'orange', 'apple', 'apple']
Scikit-learn uses real-valued features:
# Input to the classifier # 0: bumpy # 1: smooth features = [ [140, 1], [130, 1], [150, 0], [170, 0], ] # Output that we want from classifier # 0: orange # 1: apple labels = [0, 0, 1, 1]
2.7.3. What Makes a Good Feature?

Figure 2.45. Features and labels. Features are input to classifier and labels are output from it.
Using one feature?
import numpy as np
import matplotlib.pyplot as plt
greyhounds = 500
labradors = 500
# Height in centimeters + 10cm variation
greyhounds_height = 70 + 10 * np.random.randn(greyhounds)
labradors_height = 60 + 10 * np.random.randn(labradors)
plt.hist(
[greyhounds_height, labradors_height],
stacked=True,
color=['red', 'blue']
)
plt.show() # doctest: +SKIP
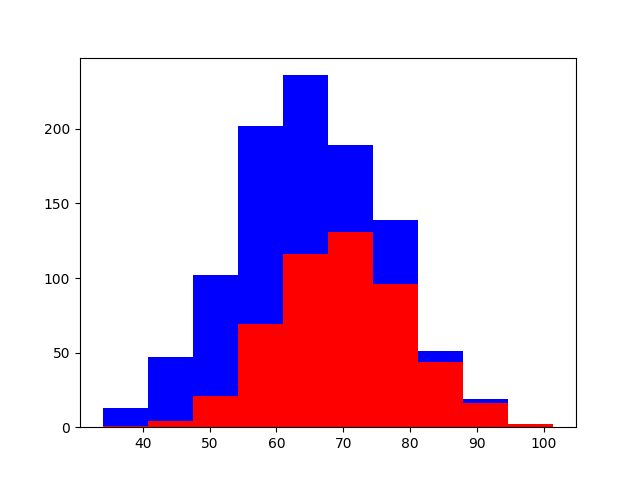
Figure 2.46. Dogs height Classification Probability
How many features do you need?
What features are good?
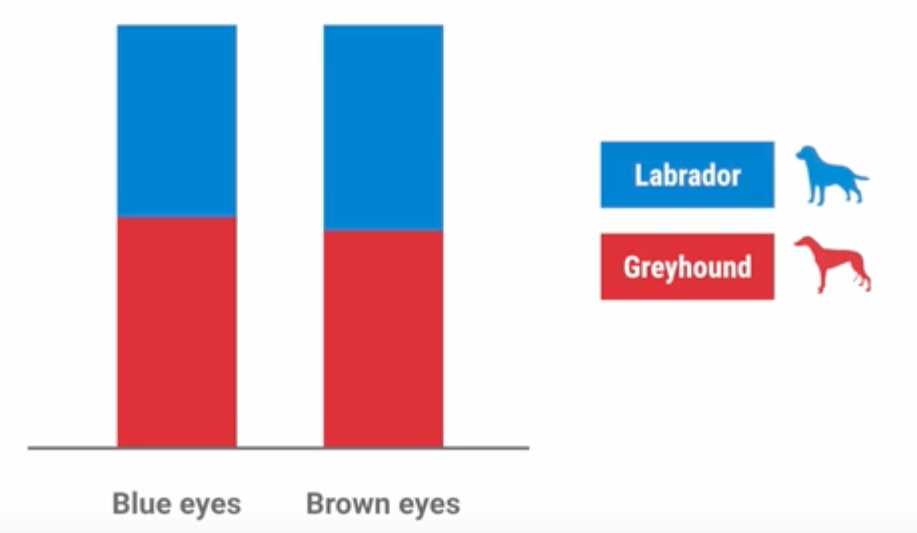
Figure 2.47. Is this a good feature for classifier? Why?
Avoid useless features, it might lower classifier accuracy.
Independent features are the best. Avoid redundant features.
Dependent features looks like this:
Height in inches
Height in centimeters
Easy to understand features.
Look for informative features.
2.7.4. Assignments
2.7.4.1. Feature Engineering
- About:
Name: Feature Engineering
Difficulty: easy
Lines: 15
Minutes: 13
- License:
Copyright 2025, Matt Harasymczuk <matt@python3.info>
This code can be used only for learning by humans (self-education)
This code cannot be used for teaching others (trainings, bootcamps, etc.)
This code cannot be used for teaching LLMs and AI algorithms
This code cannot be used in commercial or proprietary products
This code cannot be distributed in any form
This code cannot be changed in any form outside of training course
This code cannot have its license changed
If you use this code in your product, you must open-source it under GPLv2
Exception can be granted only by the author (Matt Harasymczuk)
- English:
The goal of the assignment is to create a table of features of people that make them astronauts.
It is important to select appropriate feature columns and enter values.
You can choose counter-argument data freely.
Based on data of selected astronauts:
Create a list of features for a dozen or so personal traits
Create a CSV from the data you selected and load it using the
pandaslibraryDo
Run parameter weight test
Do your features have high significance?
Run doctests - all must succeed
- Polish:
Celem zadania będzie opracowanie tabeli, cech osób, które czynią z niego astronautę.
Istotne jest dobranie odpowiednich kolumn cech oraz wpisanie wartości
Dane kontrargumentowe możesz dobrać dowolnie
Na podstawie danych wybranych astronautów:
Stwórz listę features dla kilkunastu cech osób
Stwórz CSV z wybranych przez Ciebie danych i załaduj za pomocą biblioteki
pandasDo
Uruchom test wagi parametrów
Czy Twoje features mają wysokie znaczenie?
Uruchom doctesty - wszystkie muszą się powieść
- Hints:
np.genfromtxt()np.array()i.transpose()
from sklearn import preprocessing features = ["paris", "paris", "tokyo", "amsterdam"] label_encoder = preprocessing.LabelEncoder() labels = label_encoder.fit_transform() # array([1, 1, 2, 0]) list(label_encoder.classes_) # ['amsterdam', 'paris', 'tokyo']
from sklearn import preprocessing from sklearn.ensemble import ExtraTreesClassifier # Normalize the features so that it does not affect the learning algorithm preprocessing.normalize(features) preprocessing.scale(features) # Fit the Tree algorithm # This class implements a meta estimator that fits a number of randomized decision trees (a.k.a. extra-trees) on various sub-samples of the dataset and use averaging to improve the predictive accuracy and control over-fitting. model = ExtraTreesClassifier() model.fit(features, labels) # display the relative importance of each attribute print(model.feature_importances_)
headers = set()
with open('../_data/astro-experience.csv') as file:
for line in file:
for element in line.split(','):
headers.add(element.strip())
headers = sorted(headers)
print(headers)
with open('../_data/astro-experience.csv') as file:
for line in file:
vector = []
features = [f.strip() for f in line.split(',')]
for element in headers:
if element in features:
vector.append(1)
else:
vector.append(0)
print(vector)