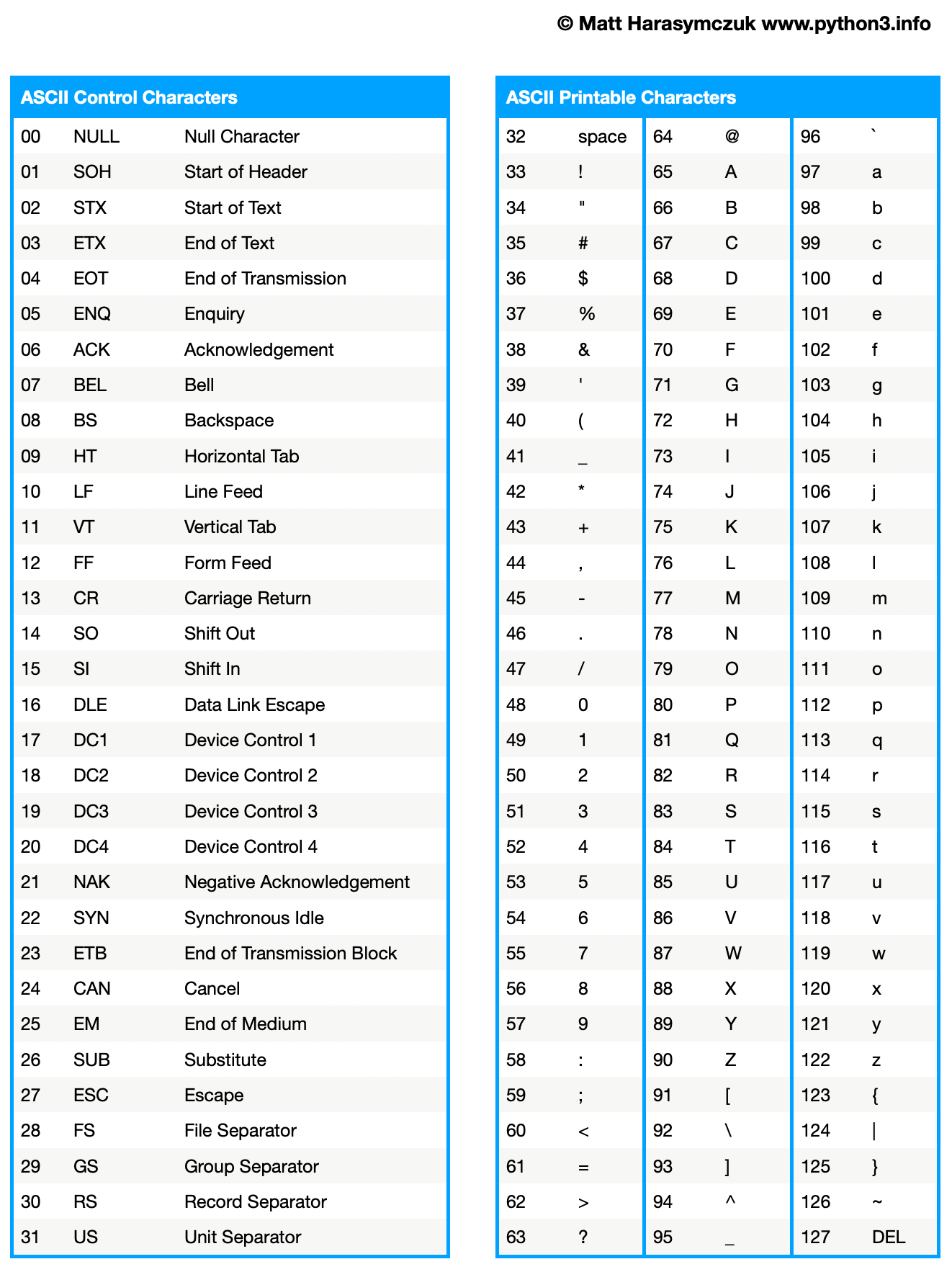
7.12. Regex Character Class
\w- any unicode alphabet character: lowercase, uppercase, numbers, underscores, national characters\W- anything but any unicode alphabet character (i.e. whitespace, dots, comas, dashes)lowercase letters
uppercase letters
digits
underscores (
_)national characters: ąćęłńóśżź... and ĄĆĘŁŃÓŚŻŹ... (uppercase and lowercase)
Word-character characters:
>>> imie = 'Alice'
>>> IMIE = 'Alice'
>>> imię = 'Alice'
>>> imię1 = 'Alice'
>>> Imię_1 = 'Alice'
7.12.1. SetUp
>>> import re
7.12.2. Character Class
Valid characters are the same as allowed in variable/modules names in Python:
>>> string = 'Email from Alice Apricot <alice@example.com> received on: Jan 1st, 2000 at 12:00AM'
>>> pattern = r'\w'
>>>
>>> re.findall(pattern, string)
['E', 'm', 'a', 'i', 'l', 'f', 'r', 'o', 'm', 'A', 'l', 'i', 'c',
'e', 'A', 'p', 'r', 'i', 'c', 'o', 't', 'a', 'l', 'i', 'c', 'e',
'e', 'x', 'a', 'm', 'p', 'l', 'e', 'c', 'o', 'm', 'r', 'e', 'c',
'e', 'i', 'v', 'e', 'd', 'o', 'n', 'J', 'a', 'n', '1', 's', 't',
'2', '0', '0', '0', 'a', 't', '1', '2', '0', '0', 'A', 'M']
7.12.3. Negation
>>> string = 'Email from Alice Apricot <alice@example.com> received on: Jan 1st, 2000 at 12:00AM'
>>> pattern = r'\W'
>>>
>>> re.findall(pattern, string)
[' ', ' ', ' ', ' ', '<', '@', '.', '>', ' ', ' ', ':', ' ', ' ', ',', ' ', ' ', ' ', ':']
7.12.4. Flags
re.UNICODE- matches national characters (uppercase and lowercase) while using\wand\Wre.ASCII- matches only ASCII characters, can potentially improve speed in string where national characters are not usedre.Uis an alias forre.UNICODEre.Ais an alias forre.ASCIIBy default,
re.UNICODEflag is turned on
Unicode:
>>> string = 'cześć'
>>>
>>> pattern = r'[a-z]'
>>> re.findall(pattern, string)
['c', 'z', 'e']
>>>
>>> pattern = r'\w'
>>> re.findall(pattern, string)
['c', 'z', 'e', 'ś', 'ć']
With flag re.UNICODE Python will also match national characters
(uppercase and lowercase) while using \w and \W. Setting flag
re.ASCII can turn off this behavior, and narrow down matches to ASCII
characters which can potentially improve speed, in strings where national
characters are not used. Flag re.UNICODE is set by default:
>>> pattern = r'\w'
>>> re.findall(pattern, string)
['c', 'z', 'e', 'ś', 'ć']
>>>
>>> pattern = r'\w'
>>> re.findall(pattern, string, flags=re.UNICODE)
['c', 'z', 'e', 'ś', 'ć']
>>>
>>> pattern = r'\w'
>>> re.findall(pattern, string, flags=re.ASCII)
['c', 'z', 'e']
7.12.5. Case Study 1
import re
CODE = """
imie = "Alice"
print(imie)
"""
variable = re.findall(r'^([a-z]+) =', CODE, flags=re.MULTILINE)
print(variable)
import re
CODE = """
Imie = "Alice"
print(Imie)
"""
variable = re.findall(r'^([a-zA-Z]+) =', CODE, flags=re.MULTILINE)
print(variable)
import re
CODE = """
Imie1 = "Alice"
print(Imie1)
"""
variable = re.findall(r'^([a-zA-Z0-9]+) =', CODE, flags=re.MULTILINE)
print(variable)
import re
CODE = """
Imie_1 = "Alice"
print(Imie_1)
"""
variable = re.findall(r'^([a-zA-Z0-9_]+) =', CODE, flags=re.MULTILINE)
print(variable)
import re
CODE = """
Imię_1 = "Alice"
print(Imię_1)
"""
variable = re.findall(r'^([a-zA-Z0-9_ąężżćńłśóĄĘŻŻĆŃŁŚÓ]+) =', CODE, flags=re.MULTILINE)
print(variable)
import re
CODE = """
Imię_1 = "Alice"
print(Imię_1)
"""
variable = re.findall(r'^(\w+) =', CODE, flags=re.MULTILINE)
print(variable)
7.12.6. Assignments
# %% About
# - Name: RE Syntax WordCharacter
# - Difficulty: easy
# - Lines: 3
# - Minutes: 1
# %% License
# - Copyright 2025, Matt Harasymczuk <matt@python3.info>
# - This code can be used only for learning by humans
# - This code cannot be used for teaching others
# - This code cannot be used for teaching LLMs and AI algorithms
# - This code cannot be used in commercial or proprietary products
# - This code cannot be distributed in any form
# - This code cannot be changed in any form outside of training course
# - This code cannot have its license changed
# - If you use this code in your product, you must open-source it under GPLv2
# - Exception can be granted only by the author
# %% English
# 1. Define `result: str` with regular expression pattern to find
# word characters
# example: ['A', 'A', 'M', 'C', 'C', 'D', 'R', ...]
# 2. Define only regex pattern (str), not re.findall(...)
# 3. Run doctests - all must succeed
# %% Polish
# 1. Zdefiniuj `result: str` z wzorcem wyrażenia regularnego aby wyszukać
# znaki słów (word characters)
# przykład: ['A', 'A', 'M', 'C', 'C', 'D', 'R', ...]
# 2. Zdefiniuj tylko wzorzec regex (str), nie re.findall(...)
# 3. Uruchom doctesty - wszystkie muszą się powieść
# %% Expected
# >>> result
# ['A', 'p', 'o', 'l', 'l', 'o', '1', '1', 'w', 'a', 's', 't', 'h', 'e',
# 'A', 'm', 'e', 'r', 'i', 'c', 'a', 'n', 's', 'p', 'a', 'c', 'e', 'f',
# 'l', 'i', 'g', 'h', 't', 't', 'h', 'a', 't', 'f', 'i', 'r', 's', 't',
# ...,
# 'h', 'o', 'u', 'r', 's', '3', '6', 'm', 'i', 'n', 'u', 't', 'e', 's',
# 'b', 'e', 'f', 'o', 'r', 'e', 'l', 'i', 'f', 't', 'i', 'n', 'g', 'o',
# 'f', 'f', 't', 'o', 'r', 'e', 'j', 'o', 'i', 'n', 'C', 'o', 'l', 'u',
# 'm', 'b', 'i', 'a']
# %% References
# [1] Authors: Wikipedia contributors
# Title: Apollo 11
# Publisher: Wikipedia
# Year: 2019
# Retrieved: 2019-12-14
# URL: https://en.wikipedia.org/wiki/Apollo_11
# %% Doctests
"""
>>> import sys; sys.tracebacklimit = 0
>>> assert sys.version_info >= (3, 9), \
'Python has an is invalid version; expected: `3.9` or newer.'
>>> from pprint import pprint
>>> result = re.findall(result, DATA)
>>> pprint(result, compact=True, width=72)
['A', 'p', 'o', 'l', 'l', 'o', '1', '1', 'w', 'a', 's', 't', 'h', 'e',
'A', 'm', 'e', 'r', 'i', 'c', 'a', 'n', 's', 'p', 'a', 'c', 'e', 'f',
'l', 'i', 'g', 'h', 't', 't', 'h', 'a', 't', 'f', 'i', 'r', 's', 't',
'l', 'a', 'n', 'd', 'e', 'd', 'h', 'u', 'm', 'a', 'n', 's', 'o', 'n',
't', 'h', 'e', 'M', 'o', 'o', 'n', 'C', 'o', 'm', 'm', 'a', 'n', 'd',
'e', 'r', 'C', 'D', 'R', 'N', 'e', 'i', 'l', 'A', 'r', 'm', 's', 't',
'r', 'o', 'n', 'g', 'a', 'n', 'd', 'l', 'u', 'n', 'a', 'r', 'm', 'o',
'd', 'u', 'l', 'e', 'p', 'i', 'l', 'o', 't', 'L', 'M', 'P', 'B', 'u',
'z', 'z', 'A', 'l', 'd', 'r', 'i', 'n', 'l', 'a', 'n', 'd', 'e', 'd',
't', 'h', 'e', 'A', 'p', 'o', 'l', 'l', 'o', 'L', 'u', 'n', 'a', 'r',
'M', 'o', 'd', 'u', 'l', 'e', 'L', 'M', 'E', 'a', 'g', 'l', 'e', 'o',
'n', 'J', 'u', 'l', 'y', '2', '0', 't', 'h', '1', '9', '6', '9', 'a',
't', '2', '0', '1', '7', 'U', 'T', 'C', 'a', 'n', 'd', 'A', 'r', 'm',
's', 't', 'r', 'o', 'n', 'g', 'b', 'e', 'c', 'a', 'm', 'e', 't', 'h',
'e', 'f', 'i', 'r', 's', 't', 'p', 'e', 'r', 's', 'o', 'n', 't', 'o',
's', 't', 'e', 'p', 'E', 'V', 'A', 'o', 'n', 't', 'o', 't', 'h', 'e',
'M', 'o', 'o', 'n', 's', 's', 'u', 'r', 'f', 'a', 'c', 'e', 'E', 'V',
'A', '6', 'h', 'o', 'u', 'r', 's', '3', '9', 'm', 'i', 'n', 'u', 't',
'e', 's', 'l', 'a', 't', 'e', 'r', 'o', 'n', 'J', 'u', 'l', 'y', '2',
'1', 's', 't', '1', '9', '6', '9', 'a', 't', '0', '2', '5', '6', '1',
'5', 'U', 'T', 'C', 'A', 'l', 'd', 'r', 'i', 'n', 'j', 'o', 'i', 'n',
'e', 'd', 'h', 'i', 'm', '1', '9', 'm', 'i', 'n', 'u', 't', 'e', 's',
'l', 'a', 't', 'e', 'r', 'T', 'h', 'e', 'y', 's', 'p', 'e', 'n', 't',
'2', 'h', 'o', 'u', 'r', 's', '3', '1', 'm', 'i', 'n', 'u', 't', 'e',
's', 'e', 'x', 'p', 'l', 'o', 'r', 'i', 'n', 'g', 't', 'h', 'e', 's',
'i', 't', 'e', 't', 'h', 'e', 'y', 'h', 'a', 'd', 'n', 'a', 'm', 'e',
'd', 'T', 'r', 'a', 'n', 'q', 'u', 'i', 'l', 'i', 't', 'y', 'B', 'a',
's', 'e', 'u', 'p', 'o', 'n', 'l', 'a', 'n', 'd', 'i', 'n', 'g', 'A',
'r', 'm', 's', 't', 'r', 'o', 'n', 'g', 'a', 'n', 'd', 'A', 'l', 'd',
'r', 'i', 'n', 'c', 'o', 'l', 'l', 'e', 'c', 't', 'e', 'd', '4', '7',
'5', 'p', 'o', 'u', 'n', 'd', 's', '2', '1', '5', 'k', 'g', 'o', 'f',
'l', 'u', 'n', 'a', 'r', 'm', 'a', 't', 'e', 'r', 'i', 'a', 'l', 't',
'o', 'b', 'r', 'i', 'n', 'g', 'b', 'a', 'c', 'k', 't', 'o', 'E', 'a',
'r', 't', 'h', 'a', 's', 'p', 'i', 'l', 'o', 't', 'M', 'i', 'c', 'h',
'a', 'e', 'l', 'C', 'o', 'l', 'l', 'i', 'n', 's', 'C', 'M', 'P', 'f',
'l', 'e', 'w', 't', 'h', 'e', 'C', 'o', 'm', 'm', 'a', 'n', 'd', 'M',
'o', 'd', 'u', 'l', 'e', 'C', 'M', 'C', 'o', 'l', 'u', 'm', 'b', 'i',
'a', 'i', 'n', 'l', 'u', 'n', 'a', 'r', 'o', 'r', 'b', 'i', 't', 'a',
'n', 'd', 'w', 'e', 'r', 'e', 'o', 'n', 't', 'h', 'e', 'M', 'o', 'o',
'n', 's', 's', 'u', 'r', 'f', 'a', 'c', 'e', 'f', 'o', 'r', '2', '1',
'h', 'o', 'u', 'r', 's', '3', '6', 'm', 'i', 'n', 'u', 't', 'e', 's',
'b', 'e', 'f', 'o', 'r', 'e', 'l', 'i', 'f', 't', 'i', 'n', 'g', 'o',
'f', 'f', 't', 'o', 'r', 'e', 'j', 'o', 'i', 'n', 'C', 'o', 'l', 'u',
'm', 'b', 'i', 'a']
"""
# %% Run
# - PyCharm: right-click in the editor and `Run Doctest in ...`
# - PyCharm: keyboard shortcut `Control + Shift + F10`
# - Terminal: `python -m doctest -f -v myfile.py`
# %% Imports
import re
# %% Types
result: str
# %% Data
DATA = """Apollo 11 was the American spaceflight that first landed
humans on the Moon. Commander (CDR) Neil Armstrong and lunar module
pilot (LMP) Buzz Aldrin landed the Apollo Lunar Module (LM) Eagle on
July 20th, 1969 at 20:17 UTC, and Armstrong became the first person
to step (EVA) onto the Moon's surface (EVA) 6 hours 39 minutes later,
on July 21st, 1969 at 02:56:15 UTC. Aldrin joined him 19 minutes later.
They spent 2 hours 31 minutes exploring the site they had named
Tranquility Base upon landing. Armstrong and Aldrin collected 47.5 pounds
(21.5 kg) of lunar material to bring back to Earth as pilot Michael Collins
(CMP) flew the Command Module (CM) Columbia in lunar orbit, and were on the
Moon's surface for 21 hours 36 minutes before lifting off to rejoin
Columbia."""
# %% Result
result = r''
# %% About
# - Name: RE Syntax WordCharacter
# - Difficulty: easy
# - Lines: 3
# - Minutes: 1
# %% License
# - Copyright 2025, Matt Harasymczuk <matt@python3.info>
# - This code can be used only for learning by humans
# - This code cannot be used for teaching others
# - This code cannot be used for teaching LLMs and AI algorithms
# - This code cannot be used in commercial or proprietary products
# - This code cannot be distributed in any form
# - This code cannot be changed in any form outside of training course
# - This code cannot have its license changed
# - If you use this code in your product, you must open-source it under GPLv2
# - Exception can be granted only by the author
# %% English
# 1. Define `result: str` with regular expression pattern to find
# non-word characters
# example: ['\n', ' ', "'", '(', ')', ',', '.', ':']
# 2. Define only regex pattern (str), not re.findall(...)
# 3. Run doctests - all must succeed
# %% Polish
# 1. Zdefiniuj `result: str` z wzorcem wyrażenia regularnego aby wyszukać
# znaki nie-słów (non-word characters)
# przykład: ['\n', ' ', "'", '(', ')', ',', '.', ':']
# 2. Zdefiniuj tylko wzorzec regex (str), nie re.findall(...)
# 3. Uruchom doctesty - wszystkie muszą się powieść
# %% Expected
# >>> result
#
# %% References
# [1] Authors: Wikipedia contributors
# Title: Apollo 11
# Publisher: Wikipedia
# Year: 2019
# Retrieved: 2019-12-14
# URL: https://en.wikipedia.org/wiki/Apollo_11
# %% Doctests
"""
>>> import sys; sys.tracebacklimit = 0
>>> assert sys.version_info >= (3, 9), \
'Python has an is invalid version; expected: `3.9` or newer.'
>>> from pprint import pprint
>>> result = re.findall(result, DATA)
>>> pprint(result, compact=True, width=72)
[' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ', '\\n', ' ', ' ', ' ', '.', ' ',
' ', '(', ')', ' ', ' ', ' ', ' ', ' ', '\\n', ' ', '(', ')', ' ', ' ',
' ', ' ', ' ', ' ', ' ', ' ', '(', ')', ' ', ' ', '\\n', ' ', ',', ' ',
' ', ' ', ':', ' ', ',', ' ', ' ', ' ', ' ', ' ', ' ', '\\n', ' ', ' ',
'(', ')', ' ', ' ', ' ', "'", ' ', ' ', '(', ')', ' ', ' ', ' ', ' ',
' ', ',', '\\n', ' ', ' ', ',', ' ', ' ', ' ', ':', ':', ' ', '.', ' ',
' ', ' ', ' ', ' ', ' ', '.', '\\n', ' ', ' ', ' ', ' ', ' ', ' ', ' ',
' ', ' ', ' ', ' ', '\\n', ' ', ' ', ' ', '.', ' ', ' ', ' ', ' ', ' ',
'.', ' ', '\\n', '(', '.', ' ', ')', ' ', ' ', ' ', ' ', ' ', ' ', ' ',
' ', ' ', ' ', ' ', ' ', '\\n', '(', ')', ' ', ' ', ' ', ' ', ' ', '(',
')', ' ', ' ', ' ', ' ', ',', ' ', ' ', ' ', ' ', '\\n', "'", ' ', ' ',
' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ', '\\n', '.']
"""
# %% Run
# - PyCharm: right-click in the editor and `Run Doctest in ...`
# - PyCharm: keyboard shortcut `Control + Shift + F10`
# - Terminal: `python -m doctest -f -v myfile.py`
# %% Imports
import re
# %% Types
result: str
# %% Data
DATA = """Apollo 11 was the American spaceflight that first landed
humans on the Moon. Commander (CDR) Neil Armstrong and lunar module
pilot (LMP) Buzz Aldrin landed the Apollo Lunar Module (LM) Eagle on
July 20th, 1969 at 20:17 UTC, and Armstrong became the first person
to step (EVA) onto the Moon's surface (EVA) 6 hours 39 minutes later,
on July 21st, 1969 at 02:56:15 UTC. Aldrin joined him 19 minutes later.
They spent 2 hours 31 minutes exploring the site they had named
Tranquility Base upon landing. Armstrong and Aldrin collected 47.5 pounds
(21.5 kg) of lunar material to bring back to Earth as pilot Michael Collins
(CMP) flew the Command Module (CM) Columbia in lunar orbit, and were on the
Moon's surface for 21 hours 36 minutes before lifting off to rejoin
Columbia."""
# %% Result
result = r''