7.1. Regex About
Also known as:
re,regex,regexp,Regular Expressions
W3C HTML5 Standard [4] regexp for email field:
>>> pattern = r"^[a-zA-Z0-9.!#$%&'*+/=?^_`{|}~-]+@[a-zA-Z0-9-]+(?:\.[a-zA-Z0-9-]+)*$"
7.1.1. Python
import rere.findall()- find all occurrences of pattern in string, returnslist[str]re.finditer()- find first occurrence of pattern in string, returnsIterator[re.Match]re.search()- find first occurrence of pattern in string, returnsre.Match(stops after first match)re.match()- check if string matches pattern, used in validation: phone, email, tax id, etc., returnsre.Matchre.compile()- compile pattern into object for further use, for example in the loop, returnsre.Patternre.split()- split string by pattern, returnslist[str]re.sub()- substitute pattern in string with something else, returnsstr
7.1.2. Syntax
Character Class - what to find (single character)
Qualifiers - range to find (range)
Negation
Quantifiers - how many occurrences of preceding qualifier or character class
Groups
Look Ahead and Look Behind
Flags
Extensions
[]- Qualifier{}- Quantifier()- Groups
7.1.3. Under the Hood
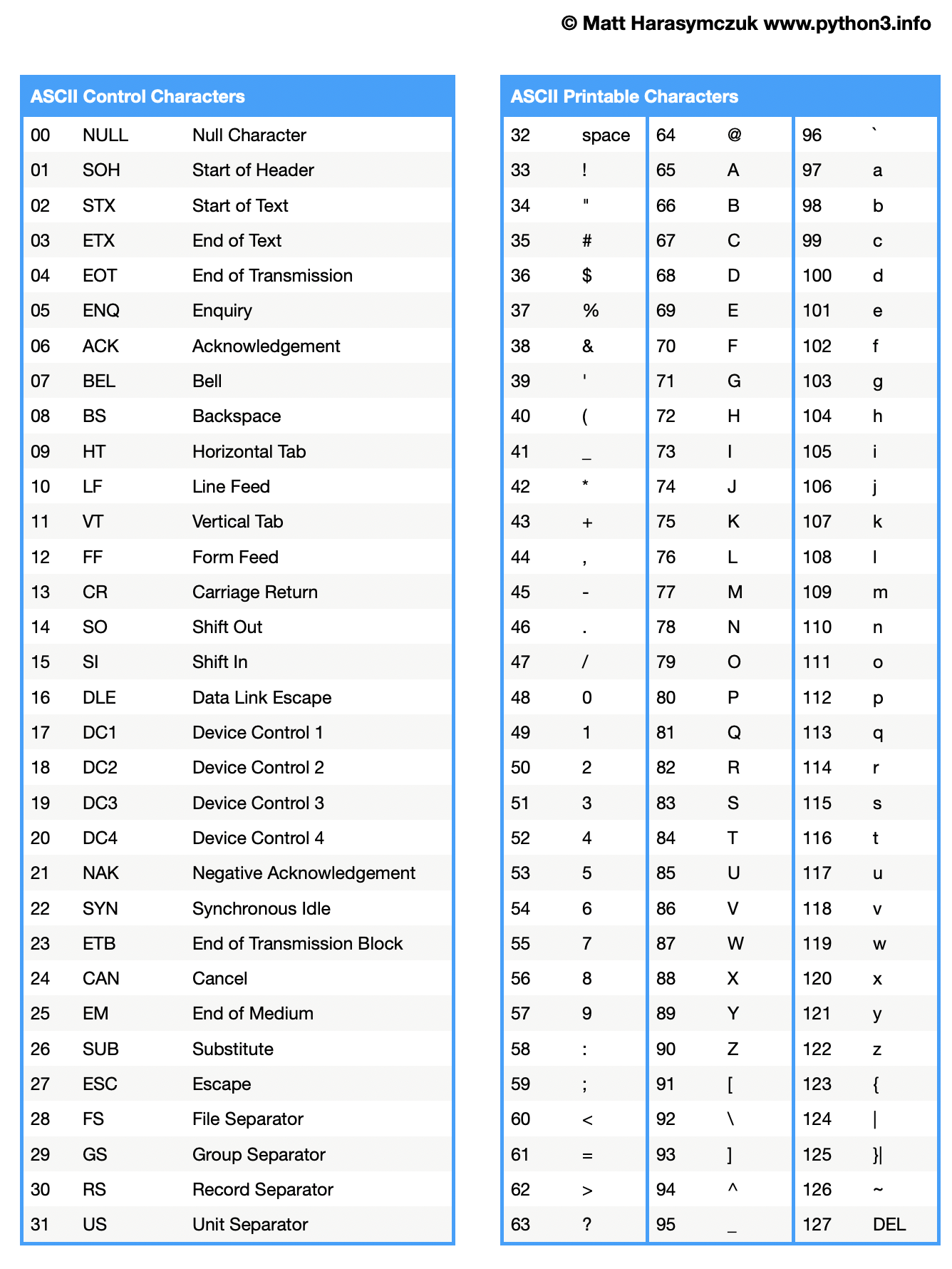
chr()- returns a string representing a character whose Unicode code point is the integer passed, for examplechr(65)returns'A'ord()- returns an integer representing the Unicode code point of the character, for exampleord('A')returns65re.DEBUG- flag to show how regular expression is parsed and executed
{kind=link}
>>> ord('A')
65
>>> string = 'Hello Alice'
>>>
>>> [ord(x) for x in string]
[72, 101, 108, 108, 111, 32, 65, 108, 105, 99, 101]
>>> import re
>>>
>>>
>>> string = 'Hello Alice'
>>>
>>> re.findall(r'A', string, flags=re.DEBUG)
LITERAL 65
0. INFO 8 0b11 1 1 (to 9)
prefix_skip 1
prefix [0x41] ('A')
overlap [0]
9: LITERAL 0x41 ('A')
11. SUCCESS
['A']
7.1.4. Visualization
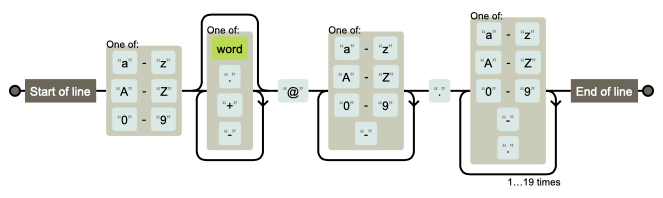
Figure 7.4. Visualization for pattern r'^[a-zA-Z0-9][\w.+-]*@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]{2,20}$' [1]
7.1.5. Further Reading
https://www.youtube.com/watch?v=BmF-gEYXWVM&list=PLv4THqSPE6meFeo_jNLgUVKkP40UstIQv&index=3
Kinsley, Harrison "Sentdex". Python 3 Programming Tutorial - Regular Expressions / Regex with re. Year: 2014. Retrieved: 2021-04-11. URL: https://www.youtube.com/watch?v=sZyAn2TW7GY
https://www.rexegg.com/regex-trick-conditional-replacement.html