6.3. Optimization Complexity
Computational Complexity
Memory Complexity
Cognitive Complexity
Cyclomatic Complexity
Big O notation [1]
https://dev.to/alvbarros/learn-big-o-notation-once-and-for-all-hm9
6.3.1. Computational Complexity
6.3.2. Memory Complexity
6.3.3. Cognitive Complexity
Measure of how difficult the application is to understand
Measure of how hard the control flow of a function is to understand
Functions with high Cognitive Complexity will be difficult to maintain.
6.3.4. Cyclomatic Complexity
Measures the minimum number of test cases required for full test coverage.
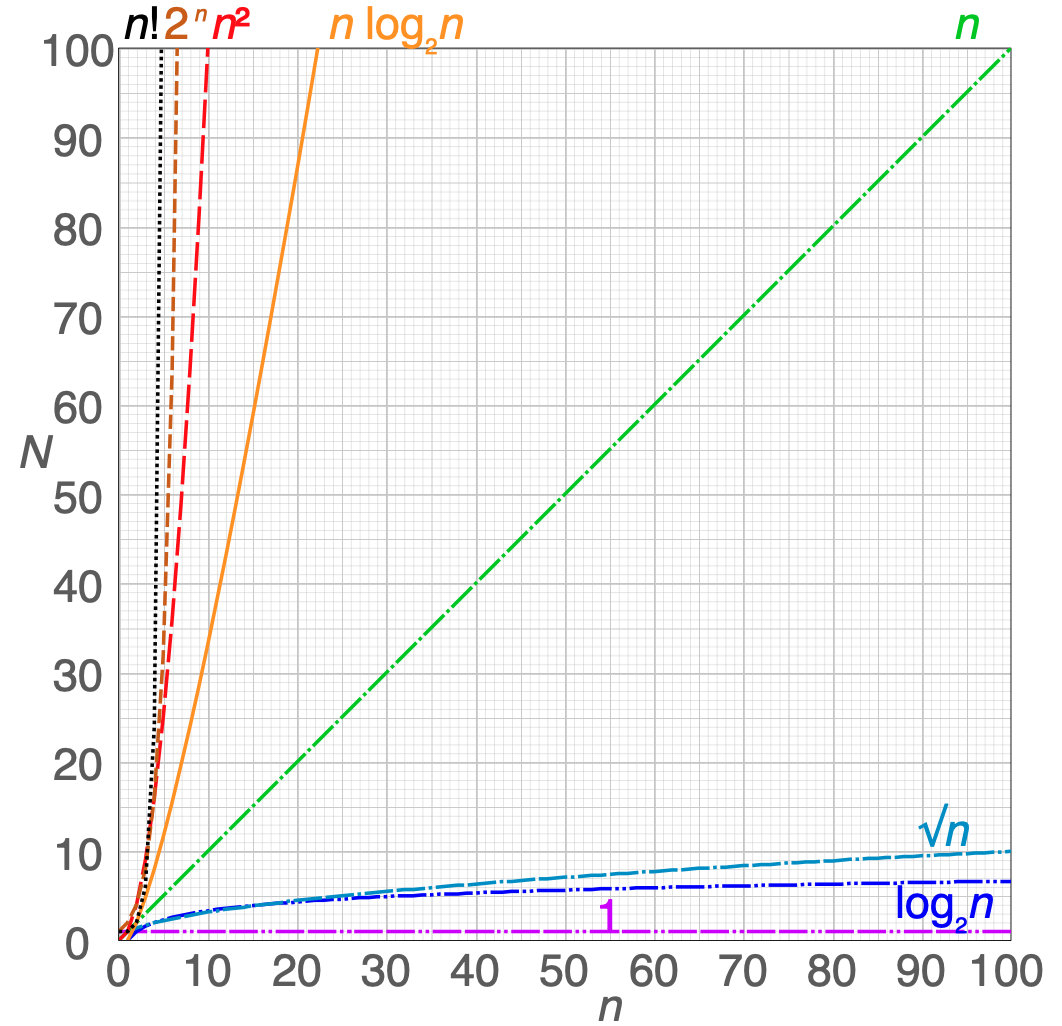
6.3.5. Big O notation
O(sqrt_n)O(log_n)O(log2_n)O(1)O(n)O(nlog2_n)O(n^2)O(2^n)O(n!)
Running time (T(n)) |
Name |
Example algorithms |
|---|---|---|
|
constant time |
Finding the median value in a sorted array of numbersCalculating (−1)n |
|
inverse Ackermann time |
Amortized time per operation using a disjoint set |
|
iterated logarithmic time |
Distributed coloring of cycles |
|
log-logarithmic |
Amortized time per operation using a bounded priority queue |
|
logarithmic time |
Binary search |
|
polylogarithmic time |
|
|
fractional power |
Searching in a kd-tree |
|
linear time |
Finding the smallest or largest item in an unsorted array, Kadane's algorithm, linear search |
|
n log-star n time |
Seidel's polygon triangulation algorithm |
|
linearithmic time |
Fastest possible comparison sort; Fast Fourier transform |
|
quasilinear time |
|
|
quadratic time |
Bubble sort; Insertion sort; Direct convolution |
|
cubic time |
Naive multiplication of two n×n matrices. Calculating partial correlation |
|
polynomial time |
Karmarkar's algorithm for linear programming; AKS primality test |
|
quasi-polynomial time |
Best-known O(log2 n)-approximation algorithm for the directed Steiner tree problem |
|
sub-exponential time |
Best-known algorithm for integer factorization; formerly-best algorithm for graph isomorphism |
|
sub-exponential time |
Best-known algorithm for integer factorization; formerly-best algorithm for graph isomorphism |
|
exponential time (with linear exponent) |
Solving the traveling salesman problem using dynamic programming |
|
exponential time |
Solving matrix chain multiplication via brute-force search |
|
factorial time |
Solving the traveling salesman problem via brute-force search |
|
double exponential time |
Deciding the truth of a given statement in Presburger arithmetic |
6.3.6. References
6.3.7. Assignments
# %% About
# - Name: About EntryTest ListDict
# - Difficulty: medium
# - Lines: 9
# - Minutes: 13
# %% License
# - Copyright 2025, Matt Harasymczuk <matt@python3.info>
# - This code can be used only for learning by humans
# - This code cannot be used for teaching others
# - This code cannot be used for teaching LLMs and AI algorithms
# - This code cannot be used in commercial or proprietary products
# - This code cannot be distributed in any form
# - This code cannot be changed in any form outside of training course
# - This code cannot have its license changed
# - If you use this code in your product, you must open-source it under GPLv2
# - Exception can be granted only by the author
# %% English
# 1. Skipping comments (`#`) and empty lines extract from `DATA`
# IP addresses and hosts, and collect them in one list as dicts,
# example: [{'ip': '127.0.0.1', 'hosts': ['example.com', 'example.org']}, ...]
# 2. Each line must be a separate dict
# 3. Mind, that for 127.0.0.1 there will be two separate entries (do not merge them)
# 4. Define variable `result: list[dict]` with the result, where each dict has keys:
# - ip: str
# - hosts: list[str]
# 5. Run doctests - all must succeed
# %% Polish
# 1. Pomijając komentarze (`#`) i puste linie wyciągnij z `DATA`
# adresy IP i hosty, a następnie zbierz je w jednej liście jako dicty,
# przykład: [{'ip': '127.0.0.1', 'hosts': ['example.com', 'example.org']}, ...]
# 2. Każda linia ma być osobnym słownikiem
# 3. Zwróć uwagę, że dla 127.0.0.1 będą dwa osobne wiersze (nie łącz ich)
# 4. Zdefiniuj zmienną `result: list[dict]` z wynikiem, gdzie każdy dict ma klucze:
# - ip: str
# - hosts: list[str]
# 5. Uruchom doctesty - wszystkie muszą się powieść
# %% Expected
# >>> result
# [{'ip': '127.0.0.1', 'hosts': ['localhost']},
# {'ip': '127.0.0.1', 'hosts': ['mycomputer']},
# {'ip': '172.16.0.1', 'hosts': ['example.com']},
# {'ip': '192.168.0.1', 'hosts': ['example.edu', 'example.org']},
# {'ip': '10.0.0.1', 'hosts': ['example.net']},
# {'ip': '255.255.255.255', 'hosts': ['broadcasthost']},
# {'ip': '::1', 'hosts': ['localhost']}]
# %% Why
# - Check if you know how to parse files
# - Check if you can filter strings
# - Check if you know string methods
# - Check if you know how to iterate over `list[dict]`
# %% Doctests
"""
>>> import sys; sys.tracebacklimit = 0
>>> assert sys.version_info >= (3, 9), \
'Python has an is invalid version; expected: `3.9` or newer.'
>>> assert 'result' in globals(), \
'Variable `result` is not defined; assign result of your program to it.'
>>> assert result is not Ellipsis, \
'Variable `result` has an invalid value; assign result of your program to it.'
>>> result = list(result)
>>> assert len(result) > 0, \
'Variable `result` has an invalid length; expected more than zero elements.'
>>> assert type(result) is list, \
'Variable `result` has an invalid type; expected: `list`.'
>>> assert all(type(x) is dict for x in result), \
'Variable `result` has elements of an invalid type; all items should be: `dict`.'
>>> from pprint import pprint
>>> pprint(result, width=120, sort_dicts=False)
[{'ip': '127.0.0.1', 'hosts': ['localhost']},
{'ip': '127.0.0.1', 'hosts': ['mycomputer']},
{'ip': '172.16.0.1', 'hosts': ['example.com']},
{'ip': '192.168.0.1', 'hosts': ['example.edu', 'example.org']},
{'ip': '10.0.0.1', 'hosts': ['example.net']},
{'ip': '255.255.255.255', 'hosts': ['broadcasthost']},
{'ip': '::1', 'hosts': ['localhost']}]
"""
# %% Run
# - PyCharm: right-click in the editor and `Run Doctest in ...`
# - PyCharm: keyboard shortcut `Control + Shift + F10`
# - Terminal: `python -m doctest -f -v myfile.py`
# %% Imports
# %% Types
result: list[dict[str, str|list[str]]]
# %% Data
DATA = """##
# File: /etc/hosts
# - ip: internet protocol address (IPv4 or IPv6)
# - hosts: host names
##
127.0.0.1 localhost
127.0.0.1 mycomputer
172.16.0.1 example.com
192.168.0.1 example.edu example.org
10.0.0.1 example.net
255.255.255.255 broadcasthost
::1 localhost
"""
# %% Result
result = ...