7.1. K Nearest Neighbors
7.1.1. Jak działa algorytm "K najbliższych sąsiadów"
Algorytm polega na:
porównaniu wartości zmiennych objaśniających dla obserwacji \(C\) z wartościami tych zmiennych dla każdej obserwacji w zbiorze uczącym.
wyborze \(k\) (ustalona z góry liczba) najbliższych do \(C\) obserwacji ze zbioru uczącego.
uśrednieniu wartości zmiennej objaśnianej dla wybranych obserwacji, w wyniku czego uzyskujemy prognozę.
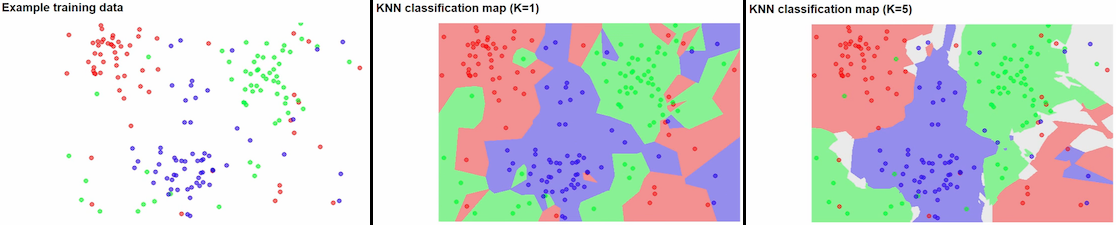
Figure 7.9. Predykcja obszaru przynależności w algorytmie "K najbliższych sąsiadów".
7.1.2. Przykład praktyczny
7.1.3. Jak to działa na przykładzie Iris
Mamy zbiór 150 obserwacji Iris
Wyobraź sobie, że mamy określić nową Iris, która jeszcze nie została zaobserwowana i opisana.
Wybieramy wartość \(k\)
Poszukujemy \(k\) obserwacji, które są najbliższe nieznanemu gatunkowi Iris.
Użyj najczęściej pojawiającej się wartości z "\(k\) najbliższych sąsiadów" jako wartość dla nieznanego Iris.
tzn. jeżeli np. dla \(k=5\) (czyli wśród 5 najbliższych Iris) było 3 Iris Setosa, i po jednym z innych gatunków
to naszemu nieznanemu gatunkowi przypiszemy Iris Setosa.
Najczęściej stosuje się algorytm Euklidesa do wyznaczania odległości, ale można również i inne algorytmy.
7.1.4. Wykorzystanie sklearn.neighbors.KNeighborsClassifier
from sklearn import datasets
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
iris = datasets.load_iris()
# Split dataset into test and training set in half
features_train, features_test, labels_train, labels_test = train_test_split(iris.data, iris.target, test_size=0.25)
# Create classifier
model = KNeighborsClassifier()
# Train classifier using training data
model.fit(features_train, labels_train)
# Predict
predictions = model.predict(features_test)
# How accurate was classifier on testing set
result = accuracy_score(labels_test, predictions)
print(result)
# Output: 0.947368421053
Because of some variation for each run, it might give different results.
7.1.5. Własna implementacja
from scipy.spatial import distance
from sklearn import datasets
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
class NearestNeighborClassifier:
def fit(self, features, labels):
self.features_train = features
self.labels_train = labels
def predict(self, features_test):
predictions = []
for row in features_test:
label = self.closest(row)
predictions.append(label)
return predictions
def closest(self, row):
best_dist = distance.euclidean(row, self.features_train[0])
best_index = 0
for i in range(0, len(self.features_train)):
dist = distance.euclidean(row, self.features_train[i])
if dist < best_dist:
best_dist = dist
best_index = i
return self.labels_train[best_index]
iris = datasets.load_iris()
# Split dataset into test and training set in half
features_train, features_test, labels_train, labels_test = train_test_split(iris.data, iris.target, test_size=0.5)
# Create classifier
model = NearestNeighborClassifier()
# Train classifier using training data
model.fit(features_train, labels_train)
# Predict
predictions = model.predict(features_test)
# How accurate was classifier on testing set
result = accuracy_score(labels_test, predictions)
print(result)
# Output: 0.96
Because of some variation for each run, it might give different results.
7.1.6. Określanie przynależności do zbioru
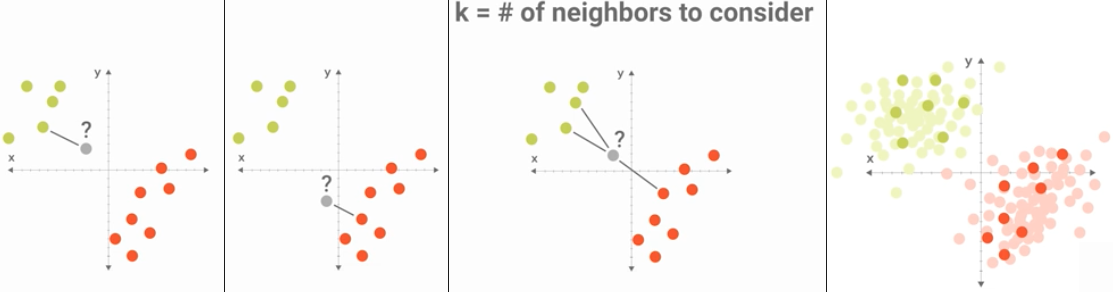
Figure 7.10. Przynależność do zbioru
7.1.7. Wyznaczanie odległości
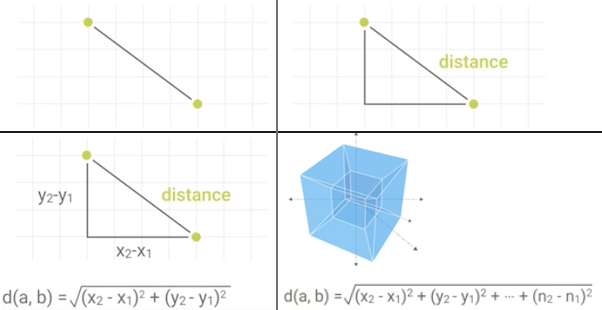
Figure 7.11. Wyliczanie odległości w celu oszacowania przynależności do zbioru. Zwróć uwagę, że bez względu na ilość wymiarów wzór się niewiele różni.
7.1.8. Zalety i wady
7.1.9. Zalety
Relatywnie prosty
Dobrze działa dla niektórych problemów
7.1.10. Wady
Wolny i zasobożerny (musi iterować dla każdej predykcji)
Brak możliwości ważenia features
7.1.11. Assignments
7.1.11.1. Pima Indians Diabetes problem
- About:
Name: Pima Indians Diabetes problem
Difficulty: medium
Lines: 15
Minutes: 13
- License:
Copyright 2025, Matt Harasymczuk <matt@python3.info>
This code can be used only for learning by humans (self-education)
This code cannot be used for teaching others (trainings, bootcamps, etc.)
This code cannot be used for teaching LLMs and AI algorithms
This code cannot be used in commercial or proprietary products
This code cannot be distributed in any form
This code cannot be changed in any form outside of training course
This code cannot have its license changed
If you use this code in your product, you must open-source it under GPLv2
Exception can be granted only by the author (Matt Harasymczuk)
- English:
...
- Polish:
Dla Pima Indians Diabetes wykonaj analizę algorytmem KNN z biblioteki
sklearn.Uruchom doctesty - wszystkie muszą się powieść
7.1.11.2. Płeć
- About:
Name: Płeć
Difficulty: easy
Lines: 15
Minutes: 13
- License:
Copyright 2025, Matt Harasymczuk <matt@python3.info>
This code can be used only for learning by humans (self-education)
This code cannot be used for teaching others (trainings, bootcamps, etc.)
This code cannot be used for teaching LLMs and AI algorithms
This code cannot be used in commercial or proprietary products
This code cannot be distributed in any form
This code cannot be changed in any form outside of training course
This code cannot have its license changed
If you use this code in your product, you must open-source it under GPLv2
Exception can be granted only by the author (Matt Harasymczuk)
- English:
...
- Polish:
Napisz własną implementacje k Nearest Neighbors, która dla danych:
Gender
Height
Weight
Foot Size
male
6.00
180
12
male
5.92
190
11
male
5.58
170
12
male
5.92
165
10
female
5.00
100
6
female
5.50
150
8
female
5.42
130
7
female
5.75
150
9
Odpowie na pytanie jaką płeć ma osoba o parametrach:
Height: 6
Weight: 130
Foot Size: 8
Jaki jest najlepszy parametr \(k\) dla tego zadania?
Która z cech ma największy wpływ?
Czy algorytm lepiej działa z:
normalizacją i skalowaniem?
bez normalizacji i skalowania?
tylko z normalizacją?
tylko skalowaniem?
Uruchom doctesty - wszystkie muszą się powieść
- Hints:
preprocessing.LabelEncoder()ExtraTreesClassifier()i.feature_importances_preprocessing.normalize(features)preprocessing.scale(features)