8.1. Naive Bayes
8.1.1. Co to jest Naiwny klasyfikator Bayesowski?
Naiwny klasyfikator Bayesowski, bazujący na twierdzeniu Bayesa, nadaje się szczególnie do problemów o bardzo wielu wymiarach na wejściu. Mimo prostoty metody, często działa ona lepiej od innych, bardzo skomplikowanych metod klasyfikujących.
\(P(A|B)\) - Jak prawdopodobna jest hipoteza, mając skutek. Prawdopodobieństwo warunkowe.
\(P(B|A)\) - Jak prawdopodobny jest dowód, zakładając że nasza hipoteza jest prawdziwa
\(P(A)\) - Jak prawdopodobna była nasza hipoteza przed zaobserwowaniem dowodów.
\(P(B)\) - Suma prawdopodobieństw wszystkich potencjalnych skutków zdarzenia: \(P(B) = \sum P(B|A)P(B)\)
8.1.2. Co to jest dokładnie?
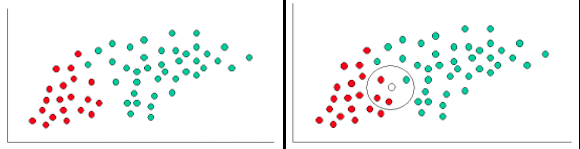
Figure 8.13. Naive Bayes
Dla ilustracji koncepcji Naiwnej metody Bayesa, rozpatrzmy przykład z powyższego rysunku. Jak widać, mamy tu obiekty zielone i czerwone. Naszym zadaniem będzie zaklasyfikowanie nowego obiektu, który może się tu pojawić.
Ponieważ zielonych kółek jest dwa razy więcej niż czerwonych, rozsądnie będzie przyjąć, że nowy obiekt (którego jeszcze nie mamy) będzie miał dwa razy większe prawdopodobieństwo bycia zielonym niż czerwonym.
W analizie Bayesowskiej, takie prawdopodobieństwa nazywane są prawdopodobieństwami a priori. Prawdopodobieństwa a priori wynikają z posiadanych, wcześniejszych (a priori) obserwacji. W tym wypadku, chodzi o procent zielonych względem czerwonych. Prawdopodobieństwa a priori często służą do przewidywania klasy nieznanych przypadków, zanim one się pojawią.
Mając obliczone prawdopodobieństwa a priori, jesteśmy gotowi do zaklasyfikowania nowego obiektu (kółko białe). Ponieważ obiekty są dobrze pogrupowane sensownie będzie założyć, że im więcej jest zielonych (albo czerwonych) obiektów w pobliżu nowego obiektu, tym bardziej prawdopodobne jest, że obiekt ten ma kolor zielony (czerwony). Narysujmy więc okrąg wokół nowego obiektu, taki by obejmował, wstępnie zadaną liczbę obiektów (niezależnie od ich klasy). Teraz będziemy mogli policzyć, ile wewnątrz okręgu jest zielonych, a ile czerwonych kółek. Skąd obliczymy wielkość, którą można nazwać szansą.
Jasne jest, że w powyższym przykładzie szansa, że X będzie czerwone jest większa niż szansa, że X będzie zielone.
Mimo, że prawdopodobieństwo a priori wskazuje, że X raczej będzie zielone (bo zielonych jest dwa razy więcej niż czerwonych), to szanse są odwrotne, ze względu na bliskość czerwonych. Końcowa klasyfikacja w analizie Bayesowskiej bazuje na obu informacjach, wg reguły Bayesa (Thomas Bayes 1702-1761).
W rezultacie klasyfikujemy X jako czerwone, gdyż większe jest prawdopodobieństwo a posteriori takiej właśnie przynależności.
8.1.3. Gaussian Naive Bayes
A Gaussian Naive Bayes algorithm is a special type of NB algorithm. It's specifically used when the features have continuous values. It's also assumed that all the features are following a gaussian distribution i.e, normal distribution.
8.1.4. Przykłady praktyczne
8.1.5. Przykład: Spam
P(spam) - prawdopodobieństwo, że wiadomość jest spamem
P(spam|words) - prawdopodobieństwo, że wiadomość jest spamem, gdy słowo należy do czarnej listy
Spam filtering based on a blacklist is flawed — it's too restrictive and false positives are too great. But Bayesian filtering gives us a middle ground — we use probabilities. As we analyze the words in a message, we can compute the chance it is spam (rather than making a yes/no decision). If a message has a 99.9% chance of being spam, it probably is. As the filter gets trained with more and more messages, it updates the probabilities that certain words lead to spam messages. Advanced Bayesian filters can examine multiple words in a row, as another data point.
8.1.6. Przykład: Apple

Figure 8.14. Naive Bayes
8.1.7. Plusy i minusy Naiwnego Bayesa
8.1.8. Plusy
Można łatwo i szybko przewidzieć kategorie testów w zestawie danych. Również dobrze się sprawdza w przewidywaniu wielu kategorii.
Mając na uwadze założenie o niezależności, Naiwny klasyfikator Bayesa wypada lepiej w porównaniu z innymi modelami, takimi jak regresja logistyczna i wymaga mniej danych treningowych.
Dobrze wypada w przypadku kategorialnego wkładu zmiennych porównanych do zmiennych liczbowych. Dla zmiennej liczbowej, założona jest rozkład normalny, co jest silnym założeniem.
8.1.9. Minusy
Jeżeli zmienna kategorialna ma kategorię (w testowanym zestawie danych), która nie została zaobserwowana w treningowym zestawie danych, wtedy model ustali zerowe prawdopodobieństwo i nie będzie w stanie niczego przewidzieć. Taką sytuację nazywa się często "Zerową Frekwencją". By to rozwiązać, możemy użyć techniki wygładzającej. Jedną z najprostszych technik wygładzających jest tzw. oszacowanie Laplace'a.
Z drugiej strony Naiwny Bayes jest także znany jako kiepski klasyfikator, więc nie zawsze należy na jego podstawie wnioskować ze 100% pewnością.
Innym ograniczeniem Naiwnego Bayesa jest założenie o niezależności wskaźników. W prawdziwym życiu, w zasadzie niemożliwym jest uzyskanie zestawu wskaźników kompletnie od siebie niezależnych.
8.1.10. Aplikacje Naiwnego klasyfikatora Bayesa
- Przewidywanie w czasie rzeczywistym
Naiwny Bayes jest skorym do nauki klasyfikatorem i z pewnością szybkim. Z tego powodu, może zostać wykorzystany do przewidywania w czasie rzeczywistym.
- Przewidywanie wielu kategorii
Ten algorytm jest również dobrze znany z cechy jaką jest przewidywanie wielu kategorii. Tutaj możemy przewidzieć prawdopodobieństwo wielu kategorii zmiennej docelowej.
- Klasyfikacja tekstu / filtrowanie spamu / analiza opinii
Naiwny Bayes klasyfikuje głównie użyte w tekście klasyfikacje (z uwagi na lepsze wyniki w problemach z wieloma kategoriami i zasadą niezależności), ma większe wskaźniki sukcesu w porównaniu z innymi algorytmami. W wyniku tego, ma szerokie zastosowanie w filtrowaniu spamu (rozpoznawanie maili ze spamem) i w analizie opinii (w analizach statystycznych dla mediów społecznościowych, by zidentyfikować pozytywne i negatywne odczucia konsumentów).
- System rekomendacyjny
Naiwny klasyfikator Bayesa razem z 'Collaborative Filtering' tworzą system rekomendacyjny, który używa uczenia się maszyn i technik eksploracji danych by filtrować niewidziane wcześniej informacje i przewidzieć czy użytkownik chciałby mieć podane źródło czy nie.
8.1.11. Przykłady praktyczne
from sklearn import datasets
from sklearn.naive_bayes import GaussianNB
iris = datasets.load_iris()
features = iris.data
labels = iris.target
model = GaussianNB()
model.fit(features, labels)
prediction = model.predict(iris.data)
points = (iris.target != prediction).sum()
print(f"Number of mislabeled points out of a total {features.shape[0]} points : {points}")
# Number of mislabeled points out of a total 150 points : 6
8.1.12. Zadanie kontrolne
8.1.13. Pima Indians Diabetes problem
Dla Pima Indians Diabetes wykonaj analizę algorytmem Naive Bayes z biblioteki sklearn.
8.1.14. Nowotwory
Co roku na raka piersi zapada ponad 1 milion kobiet. 10% z nich umiera. Wiele z nich jest źle zdiagnozowana, ponieważ nawet najlepsze mammografy dają fałszywe wyniki.
W celu polepszenia dokładności urządzeń medycznych stosuje się skomplikowane algorytmy, które zwiększają liczbę obiektywnych diagnoz. Dzięki twierdzeniu Bayesa, możemy odpowiedzieć na pytanie:
Jakie jest prawdopodobieństwo zachorowania na nowotwór przy pozytywnym wyniku z testu?
Na etapie testów klinicznych nowego mammografu przeprowadzono statystykę, której wyniki pokazują sprawność testu:
1% kobiet poddanych badaniom ma raka, stąd 99% nie ma.
90% przypadków, kiedy kobieta ma raka jest wykrywana prawidłowo, 10% z nich nie
U 20% zdrowych osób test wykrywa nowotwór.
Wynik testu |
Chory (1%) |
Zdrowy (99%) |
|---|---|---|
pozytywny |
90% |
10% |
negatywny |
20% |
80% |
Załóżmy, że dostałaś pozytywny wynik, czyli masz raka.
Jakie jest prawdopodobieństwo, że faktycznie jesteś chora?
Napisz kod bez używania bibliotek zewnętrznych.
Wzór Bayesa:
P(A|B) = P(B|A) * P(A) / P(B)
P(chory|pozytywny) = ?
P(chory) = 0.01
P(pozytywny|chory) = 0.9
P(pozytywny|zdrowy) = 0.1
P(negatywny|chory) = 0.2
P(negatywny|zdrowy) = 0.8
P(pozytywny) = 0,9*0,01 + 0,2*0,99 = 0,207
P(chory|pozytywny) = P(pozytywny|chory) * P(chory) / P(pozytywny)
P(chory|pozytywny) = 0,9 * 0,01 / 0,207 = 0,0434 = 4,3%
8.1.15. Spam Classifier
Stwórz classifier który na podstawie wiadomości email zakwalifikuje je jako SPAM lub nie SPAM.
Zakwalifikuj wiadomości poniżej:
Treść wiadomości |
|---|
Click here to claim your prize! |
What's new? |
Hang out later? |
You have won $1,000,000 in cash |
Enlarge your... |
Nigerian prince |
Money for you |
Here's the telnet address |
Make your trip in 3D! |
You will receive money! |
Hey can I call you? |
Skorzystaj treningowej bazy danych wiadomości spam: https://archive.ics.uci.edu/ml/machine-learning-databases/spambase/