6.1. Encoding About
6.1.1. Problem
>>> key = 'a'
>>>
>>> bin('a')
Traceback (most recent call last):
TypeError: 'str' object cannot be interpreted as an integer
6.1.2. Solution
>>> key = 'a'
>>>
>>> ord(key)
97
>>>
>>> bin(97)
'0b1100001'
6.1.3. Encoding
ASCII
ASCII-Extended
ISO-8859-2
CP1250
UTF-8
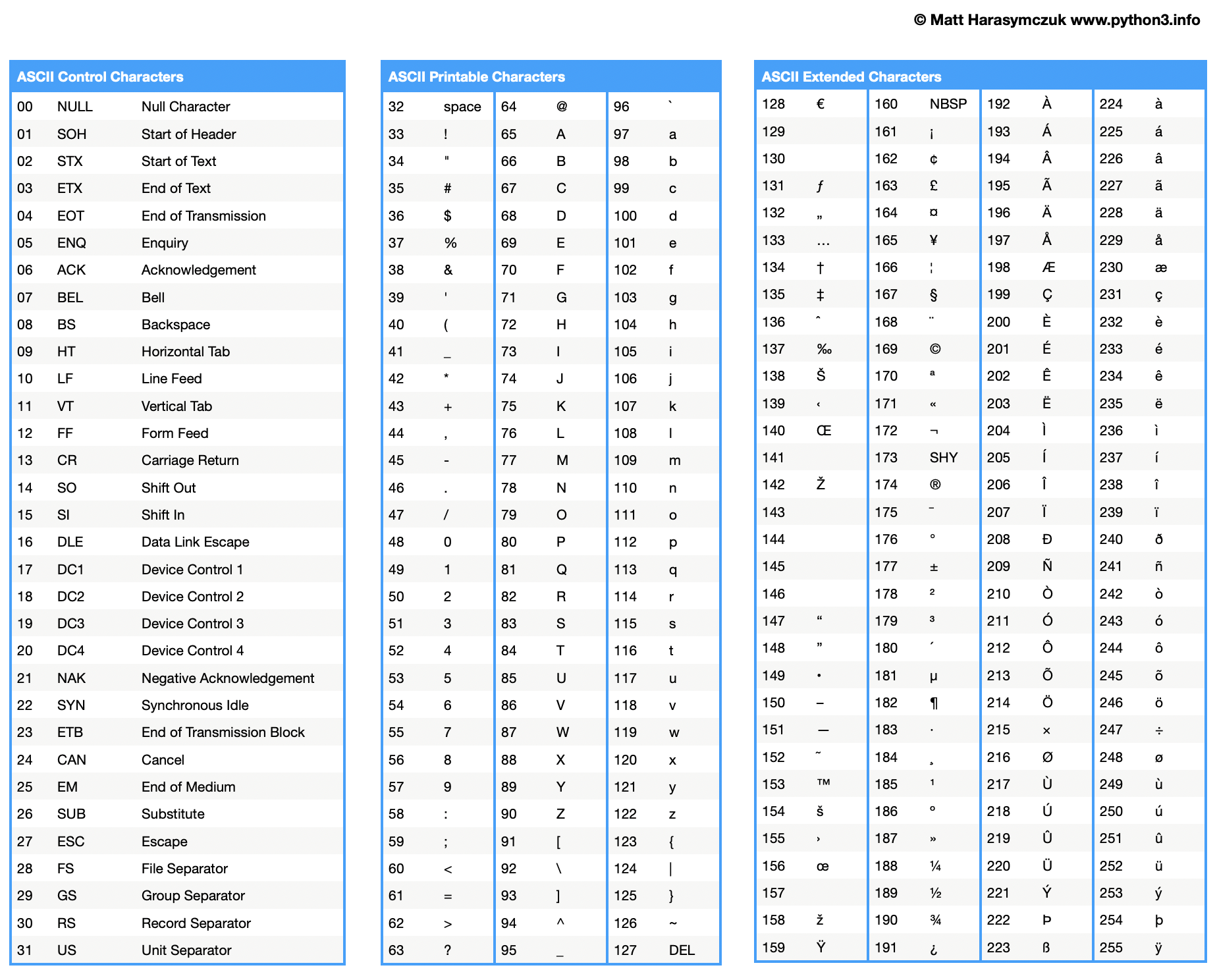
6.1.4. ASCII vs. ASCII-Extended Encoding
ASCII - American Standard Code for Information Interchange
ASCII - 7-bit encoding - from 0 to 127 (0b0000000 to 0b1111111)
ASCII-Extended - 8-bit encoding - 0 to 255 (from 0b00000000 to 0b11111111)
6.1.5. ISO Encoding
ISO - International Organization for Standardization
ISO-8859 - character encoding standard
ISO-8859-1 - Western European (Latin-1)
ISO-8859-2 - Central European (Latin-2)
ISO-8859-3 - South European (Latin-3)
ISO-8859-4 - North European (Latin-4)
ISO-8859-5 - Latin/Cyrillic
ISO-8859-6 - Latin/Arabic
ISO-8859-7 - Latin/Greek
ISO-8859-8 - Latin/Hebrew
ISO-8859-9 - Turkish (Latin-5)
ISO-8859-10 - Nordic (Latin-6)
ISO-8859-11 - Latin/Thai
ISO-8859-12 - Latin/Devanagari (abandoned)
ISO-8859-13 - Baltic Rim (Latin-7)
ISO-8859-14 - Celtic (Latin-8)
ISO-8859-15 - Latin-9 - A revision of 8859-1 with removed little-used symbols, replacing them with the euro sign € and the letters Š, š, Ž, ž, Œ, œ, and Ÿ)
ISO-8859-16 - South-Eastern European (Latin-10) - Intended for Albanian, Croatian, Hungarian, Italian, Polish, Romanian and Slovene, but also Finnish, French, German and Irish Gaelic
>>> text = 'cześć'
>>>
>>> with open('/tmp/myfile.txt', mode='wt', encoding='iso-8859-2') as file:
... file.write(text + '\n')
6
$ file /tmp/myfile.txt
/tmp/myfile.txt: ISO-8859 text
$ cat /tmp/myfile.txt
cze��
6.1.6. Windows Encoding
Windows is registered trademark of Microsoft
windows-1250is calledcp1250CP - Code Page
cp1250 - Central European languages
cp1251 - Cyrillic script
cp1252 - Western European languages
cp1253 - Greek script
cp1254 - Turkish script
cp1255 - Hebrew script
cp1256 - Arabic script
>>> text = 'cześć'
>>>
>>> with open('/tmp/myfile.txt', mode='wt', encoding='cp1250') as file:
... file.write(text + '\n')
6
$ file /tmp/myfile.txt
/tmp/myfile.txt: Non-ISO extended-ASCII text
$ cat /tmp/myfile.txt
cze��
6.1.7. Unicode Encoding
Unicode - character encoding standard
UTF-8 - Unicode Transformation Format - ASCII compatible
UTF-16 - Unicode Transformation Format - uF600
UTF-32 - Unicode Transformation Format - U0001F600
Little Endian (LE) vs. Big Endian (BE)
>>> text = 'cześć'
>>>
>>> with open('/tmp/myfile.txt', mode='wt', encoding='utf-8') as file:
... file.write(text + '\n')
6
$ file /tmp/myfile.txt
/tmp/myfile.txt: Unicode text, UTF-8 text
$ cat /tmp/myfile.txt
cześć
6.1.8. Default
UTF-8
>>> text = 'cześć'
>>>
>>> with open('/tmp/myfile.txt', mode='wt') as file:
... file.write(text + '\n')
6
$ file /tmp/myfile.txt
/tmp/myfile.txt: Unicode text, UTF-8 text
$ cat /tmp/myfile.txt
cześć