4.8. Normalization Theory
- relation
In relational database theory, a relation, as originally defined by E. F. Codd, [4] is a set of tuples (d1, d2, ..., dn), where each element dj is a member of Dj, a data domain. Codd's original definition notwithstanding, and contrary to the usual definition in mathematics, there is no ordering to the elements of the tuples of a relation. Instead, each element is termed an attribute value. An attribute is a name paired with a domain (nowadays more commonly referred to as a type or data type). An attribute value is an attribute name paired with an element of that attribute's domain, and a tuple is a set of attribute values in which no two distinct elements have the same name. Thus, in some accounts, a tuple is described as a function, mapping names to values. [6]
- retention
Data retention defines the policies of persistent data and records management for meeting legal and business data archival requirements. In the field of telecommunications, data retention generally refers to the storage of call detail records (CDRs) of telephony and internet traffic and transaction data (IPDRs) by governments and commercial organisations. In the case of government data retention, the data that is stored is usually of telephone calls made and received, emails sent and received, and websites visited. Location data is also collected. [5]
- consistency
Consistency (or Correctness) in database systems refers to the requirement that any given database transaction must change affected data only in allowed ways. Any data written to the database must be valid according to all defined rules, including constraints, cascades, triggers, and any combination thereof. This does not guarantee correctness of the transaction in all ways the application programmer might have wanted (that is the responsibility of application-level code) but merely that any programming errors cannot result in the violation of any defined database constraints. [10] [7]
- integrity
Data integrity is the maintenance of, and the assurance of, data accuracy and consistency over its entire life-cycle and is a critical aspect to the design, implementation, and usage of any system that stores, processes, or retrieves data. The term is broad in scope and may have widely different meanings depending on the specific context – even under the same general umbrella of computing. It is at times used as a proxy term for data quality, while data validation is a prerequisite for data integrity. Data integrity is the opposite of data corruption. The overall intent of any data integrity technique is the same: ensure data is recorded exactly as intended (such as a database correctly rejecting mutually exclusive possibilities). Moreover, upon later retrieval, ensure the data is the same as when it was originally recorded. In short, data integrity aims to prevent unintentional changes to information. Data integrity is not to be confused with data security, the discipline of protecting data from unauthorized parties. [9] [8]
- DBA
DataBase Administrator
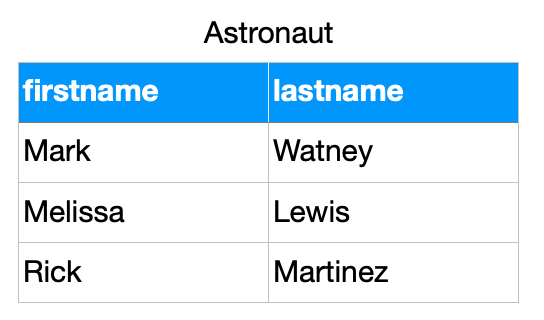
4.8.1. Base
>>> from dataclasses import dataclass
>>>
>>>
>>> @dataclass
... class Astronaut:
... firstname: str
... lastname: str
>>>
>>>
>>> CREW = [
... Astronaut('Mark', 'Watney'),
... Astronaut('Melissa', 'Lewis'),
... Astronaut('Rick', 'Martinez'),
... ]
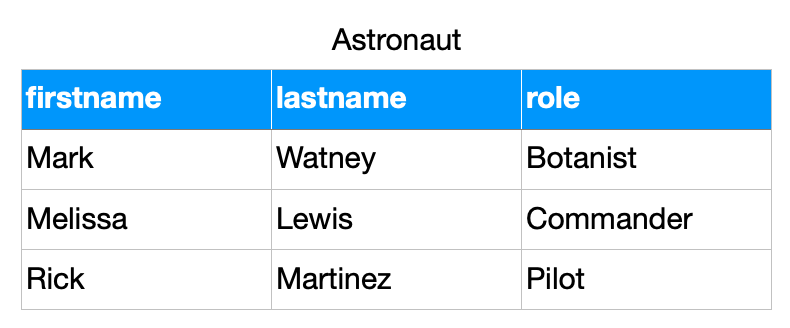
4.8.2. Extend
>>> from dataclasses import dataclass
>>>
>>>
>>> @dataclass
... class Astronaut:
... firstname: str
... lastname: str
... role: str
>>>
>>>
>>> CREW = [
... Astronaut('Mark', 'Watney', 'Botanist'),
... Astronaut('Melissa', 'Lewis', 'Commander'),
... Astronaut('Rick', 'Martinez', 'Pilot'),
... ]
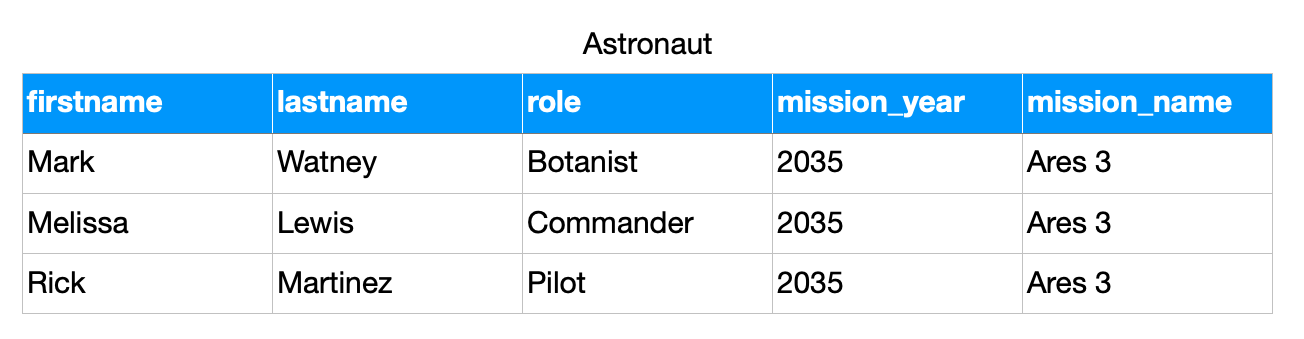
>>> from dataclasses import dataclass
>>>
>>>
>>> @dataclass
... class Astronaut:
... firstname: str
... lastname: str
... role: str
... mission_year: int
... missions_name: str
>>>
>>>
>>> CREW = [
... Astronaut('Mark', 'Watney', 'Botanist', 2035, 'Ares 3'),
... Astronaut('Melissa', 'Lewis', 'Commander', 2035, 'Ares 3'),
... Astronaut('Rick', 'Martinez', 'Pilot', 2035, 'Ares 3'),
... ]
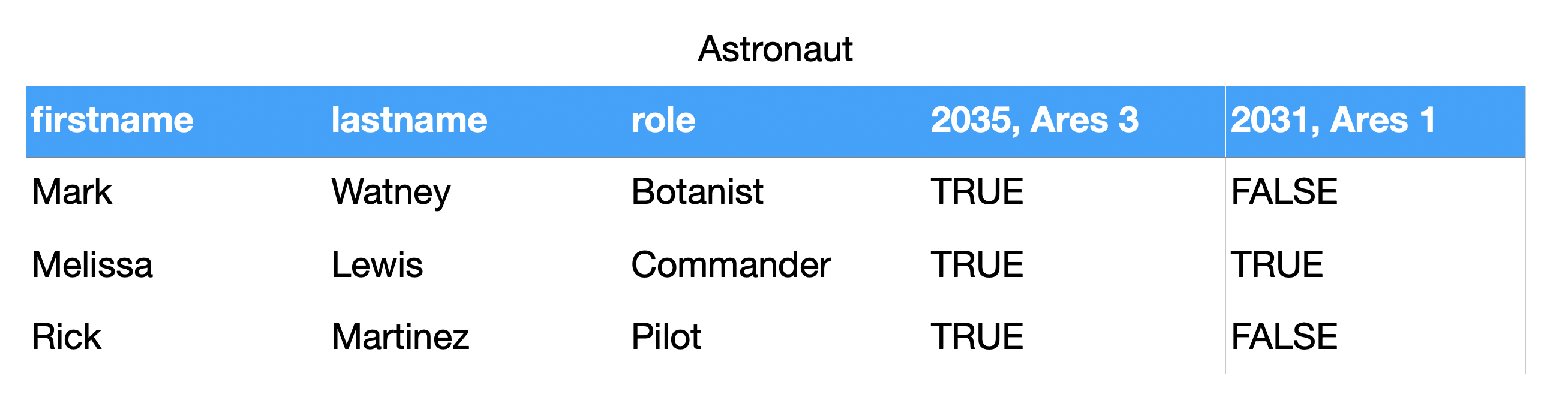
4.8.3. Boolean Vector
>>> from dataclasses import dataclass
>>>
>>>
>>> @dataclass
... class Mission:
... year: int
... name: str
>>>
>>>
>>> @dataclass
... class Astronaut:
... firstname: str
... lastname: str
... role: str
... missions: list[Mission]
>>>
>>>
>>> CREW = [
... Astronaut('Mark', 'Watney', 'Botanist', missions=[
... Mission(2035, 'Ares 3')]),
... Astronaut('Melissa', 'Lewis', 'Commander', missions=[
... Mission(2035, 'Ares 3'),
... Mission(2031, 'Ares 1')]),
... Astronaut('Rick', 'Martinez', 'Pilot', missions=[]),
... ]
4.8.4. FFill
>>> from dataclasses import dataclass
>>>
>>>
>>> @dataclass
... class Mission:
... year: int
... name: str
>>>
>>>
>>> @dataclass
... class Astronaut:
... firstname: str
... lastname: str
... role: str
... missions: list[Mission]
>>>
>>>
>>> CREW = [
... Astronaut('Mark', 'Watney', 'Botanist', missions=[
... Mission(2035, 'Ares 3')]),
... Astronaut('Melissa', 'Lewis', 'Commander', missions=[
... Mission(2035, 'Ares 3'),
... Mission(2031, 'Ares 1')]),
... Astronaut('Rick', 'Martinez', 'Pilot', missions=[]),
... ]
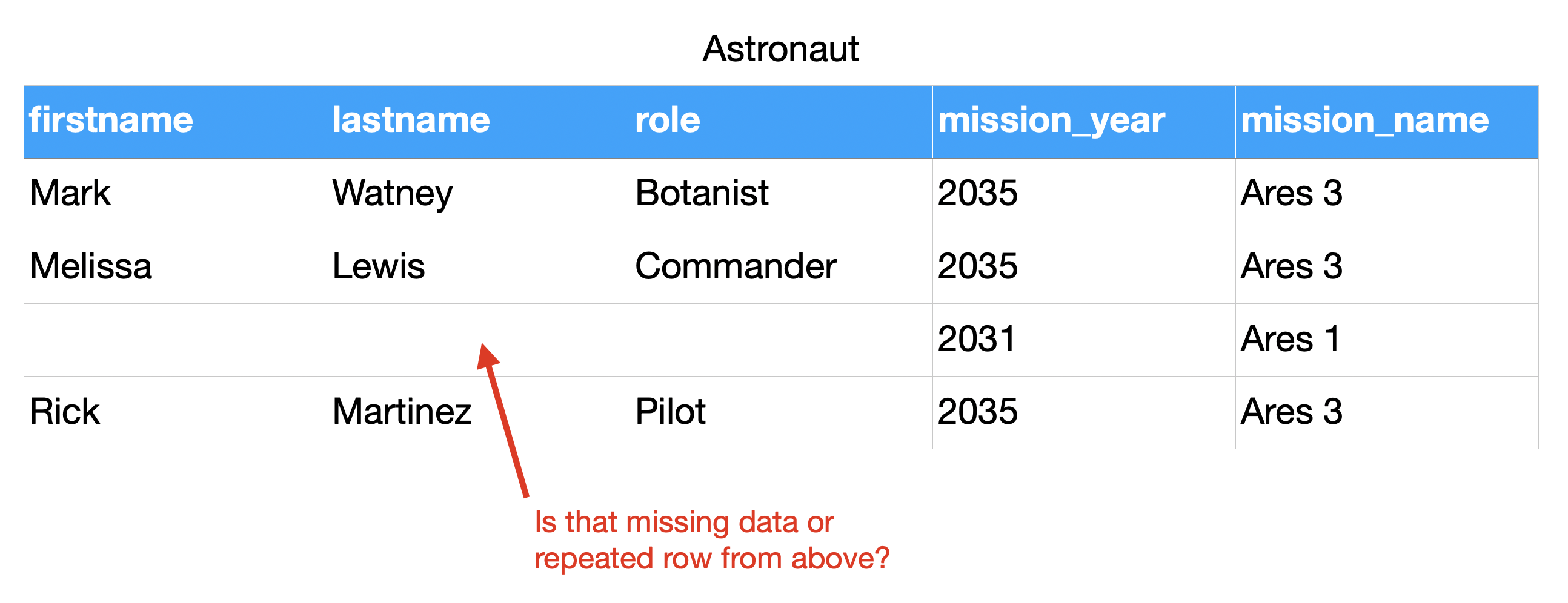
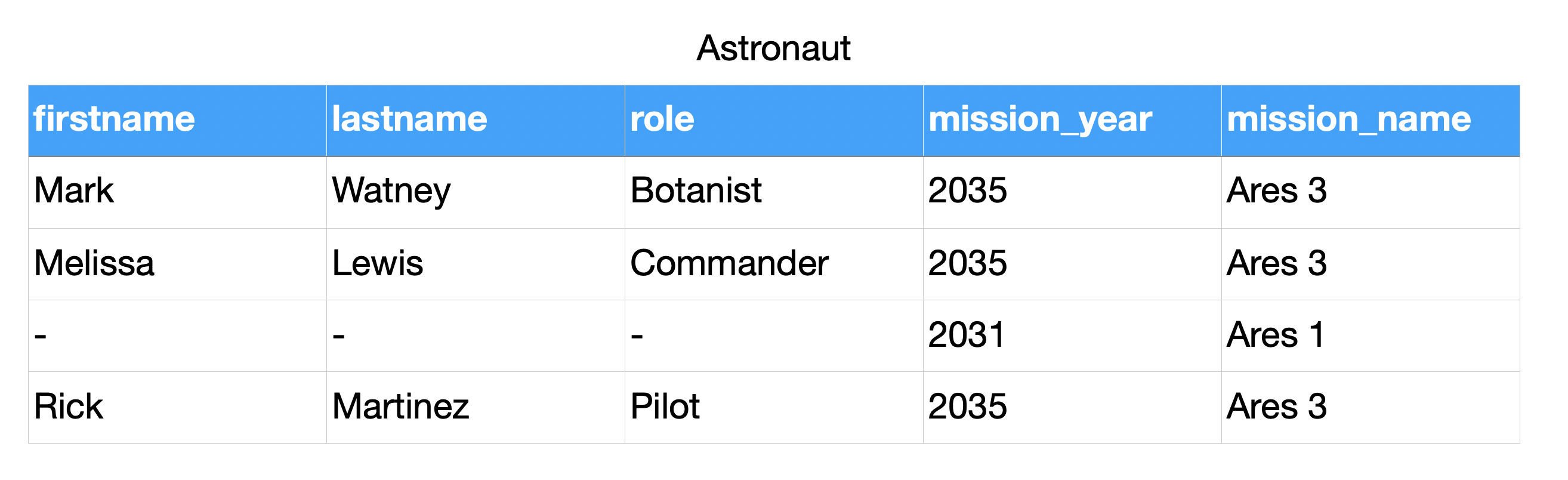

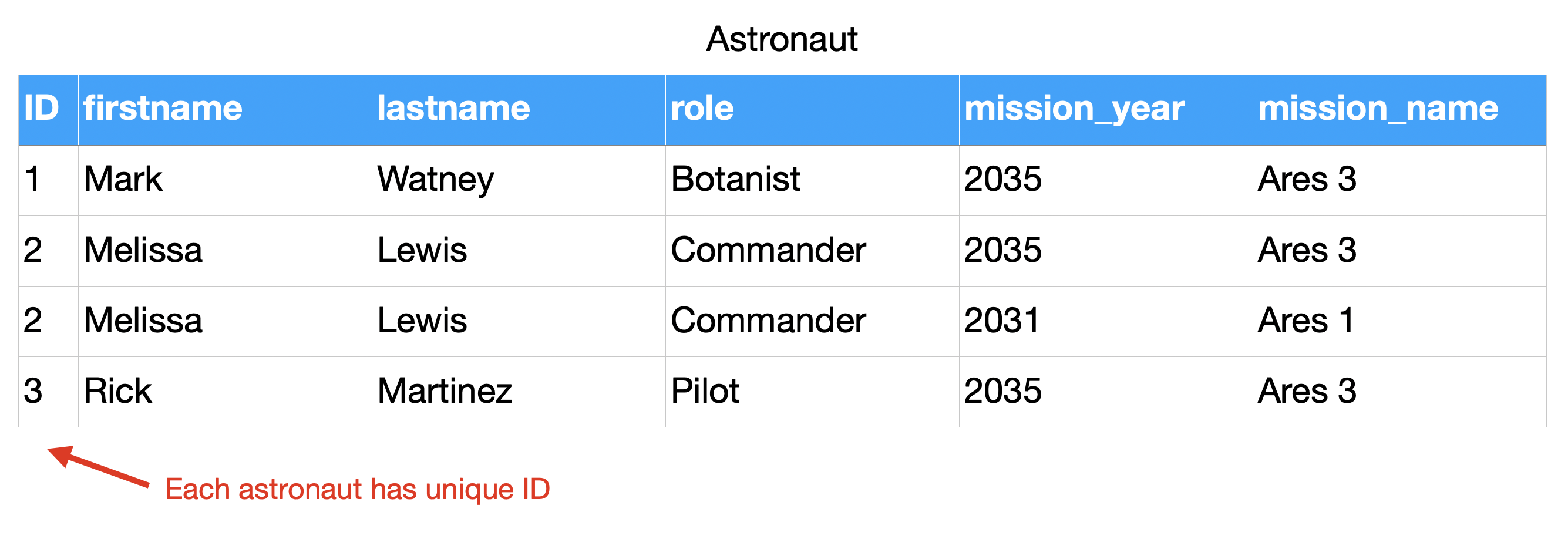
4.8.5. Relations
>>> from dataclasses import dataclass
>>>
>>>
>>> @dataclass
... class Mission:
... year: int
... name: str
>>>
>>>
>>> @dataclass
... class Astronaut:
... firstname: str
... lastname: str
... role: str
... missions: list[Mission]
>>>
>>>
>>> CREW = [
... Astronaut('Mark', 'Watney', 'Botanist', missions=[
... Mission(2035, 'Ares 3')]),
... Astronaut('Melissa', 'Lewis', 'Commander', missions=[
... Mission(2035, 'Ares 3'),
... Mission(2031, 'Ares 1')]),
... Astronaut('Rick', 'Martinez', 'Pilot', missions=[]),
... ]


4.8.6. Serialization
>>> from dataclasses import dataclass
>>>
>>>
>>> @dataclass
... class Mission:
... year: int
... name: str
>>>
>>>
>>> @dataclass
... class Astronaut:
... firstname: str
... lastname: str
... role: str
... missions: list[Mission]
>>>
>>>
>>> CREW = [
... Astronaut('Mark', 'Watney', 'Botanist', missions=[
... Mission(2035, 'Ares 3')]),
... Astronaut('Melissa', 'Lewis', 'Commander', missions=[
... Mission(2035, 'Ares 3'),
... Mission(2031, 'Ares 1')]),
... Astronaut('Rick', 'Martinez', 'Pilot', missions=[]),
... ]
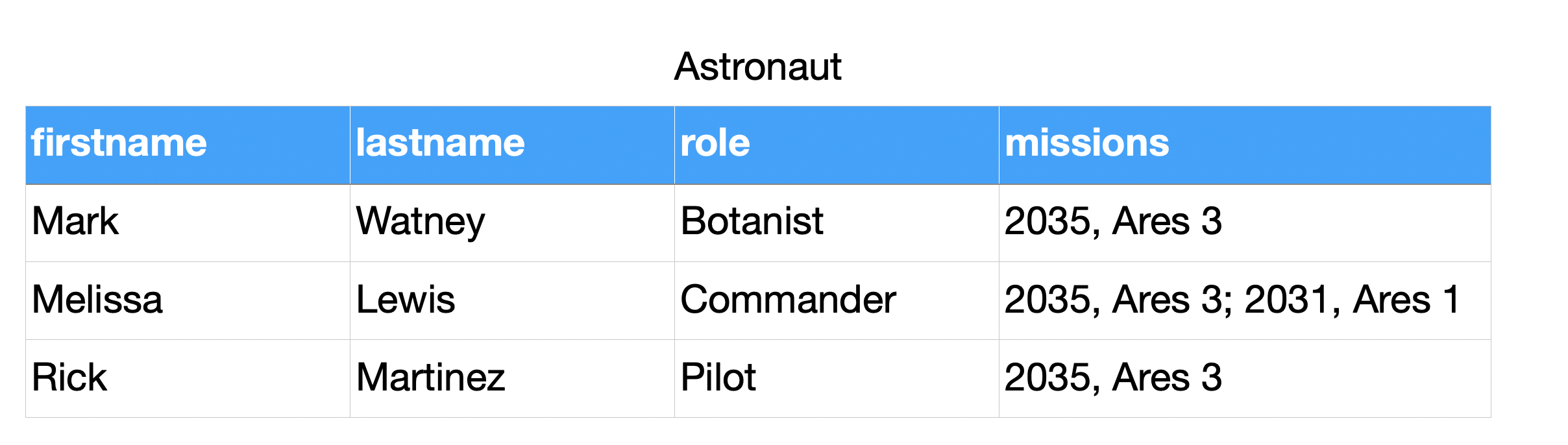
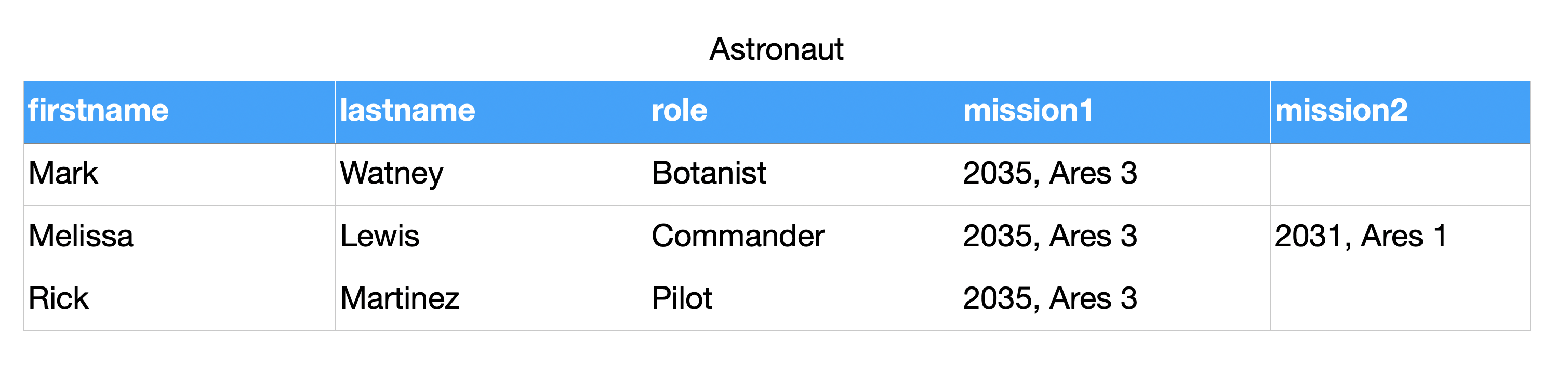
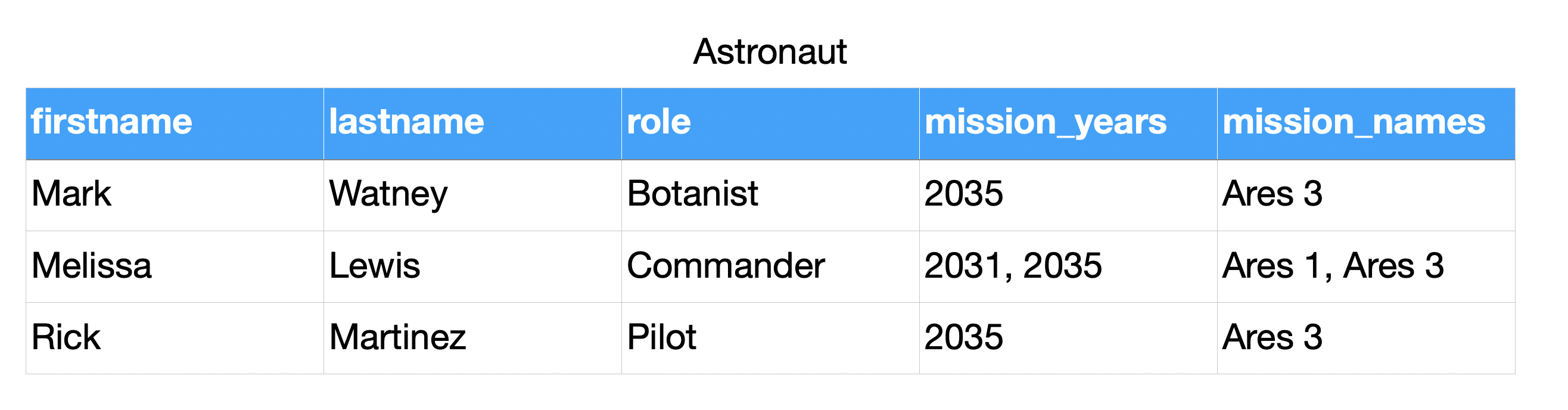

4.8.7. Normal forms
UNF: Unnormalized form
1NF: First normal form
2NF: Second normal form
3NF: Third normal form
EKNF: Elementary key normal form
BCNF: Boyce–Codd normal form
4NF: Fourth normal form
ETNF: Essential tuple normal form
5NF: Fifth normal form
DKNF: Domain-key normal form
6NF: Sixth normal form
4.8.8. Recap
DBA and Programmers use different data format than Data Scientists
Data Scientists prefer flat formats, without relations and joins
DBA and Programmers prefer relational data
For DBA and Programmers flat data formats represents data duplication
Normalization make data manipulation more consistent
Normalization uses less space and makes UPDATEs easier
Normalization causes a lot of SELECT and JOINs, which requires computation
In XXI century storage is cheap, computing power cost money
Currently SELECTs are far more common than INSERTs and UPDATEs (let say 80%-15%-5% - just a rough estimate, please don't quote this number)
Normalization does not work at large (big-data) scale
Big data requires simplified approach, and typically without any relations
Data consistency then is achieved by business logic