6.8. String Methods
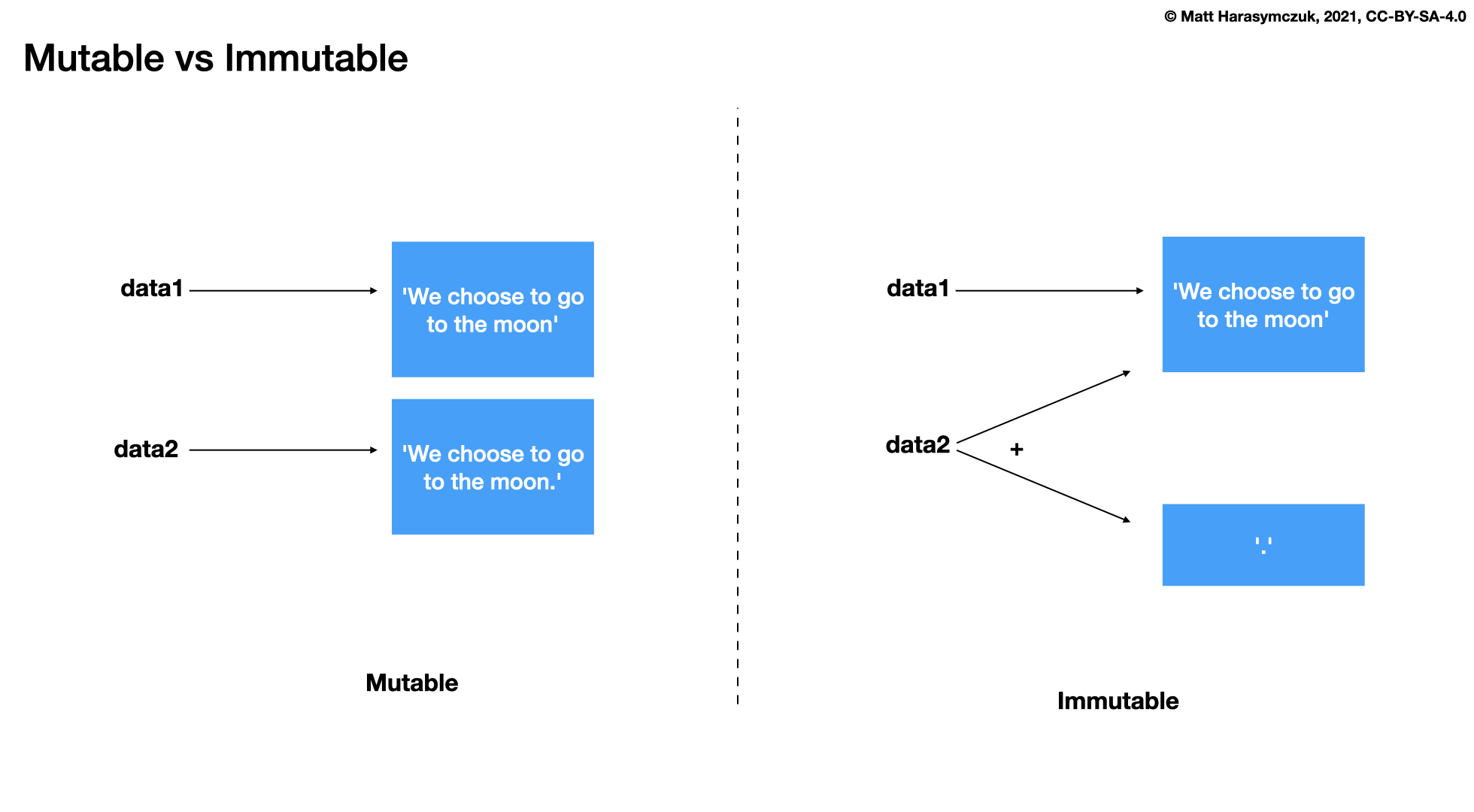
stris immutablestrmethods create a new modifiedstr
Whenever you call a method on string, it will not change that string, but it will generate a new one. You can capture this newly generated string:
>>> text = 'Alice'
>>> result = text.upper()
>>>
>>> print(result)
ALICE
>>>
>>> print(text)
Alice
You can also assign to the same variable, which will give you an impression
that this modified string, but in fact that is a new object to which
text identifier will point:
>>> text = 'Alice'
>>> text = text.upper()
>>>
>>> print(text)
ALICE
6.8.1. Memory



6.8.2. Value Check
Use
==to check if strings are equal
This is valid way to check str value:
>>> name = 'Alice'
>>>
>>> name == 'Alice'
True
6.8.3. Length
Builtin
len()returns the length of a string
>>> len('Alice')
5
6.8.4. Method Chaining
>>> name = 'Angus MacGyver 3'
>>> result = name.lower().replace('mac', 'mc').replace('3', 'III').strip().title()
>>> name = 'Angus MacGyver 3'
>>>
>>> result = (
... name
... .lower()
... .replace('mac', 'mc')
... .replace('3', 'III')
... .replace('2', 'II')
... .replace('1', 'I')
... .strip()
... .title()
... )
6.8.5. Use Case - 1
>>> DATA = 'ul. pANA tWARdoWSKiego 3'
>>>
>>> result = (
... DATA
...
... # Normalize
... .upper()
...
... # Remove whitespace control chars
... .replace('\n', ' ')
... .replace('\t', ' ')
... .replace('\v', ' ')
... .replace('\f', ' ')
...
... # Remove whitespaces
... .replace(' ', ' ')
... .replace(' ', ' ')
... .replace(' ', ' ')
...
... # Remove special characters
... .replace('$', '')
... .replace('@', '')
... .replace('#', '')
... .replace('^', '')
... .replace('&', '')
... .replace('.', '')
... .replace(',', '')
... .replace('|', '')
...
... # Remove prefixes
... .removeprefix('ULICA')
... .removeprefix('UL')
... .removeprefix('OSIEDLE')
... .removeprefix('OS')
...
... # Substitute
... .replace('3', 'III')
... .replace('2', 'II')
... .replace('1', 'I')
...
... # Format output
... .title()
... .replace('Iii', 'III')
... .replace('Ii', 'II')
... .strip()
... )
>>>
>>> print(result)
Pana Twardowskiego III