10.5. FP Apply Recap
10.5.1. About
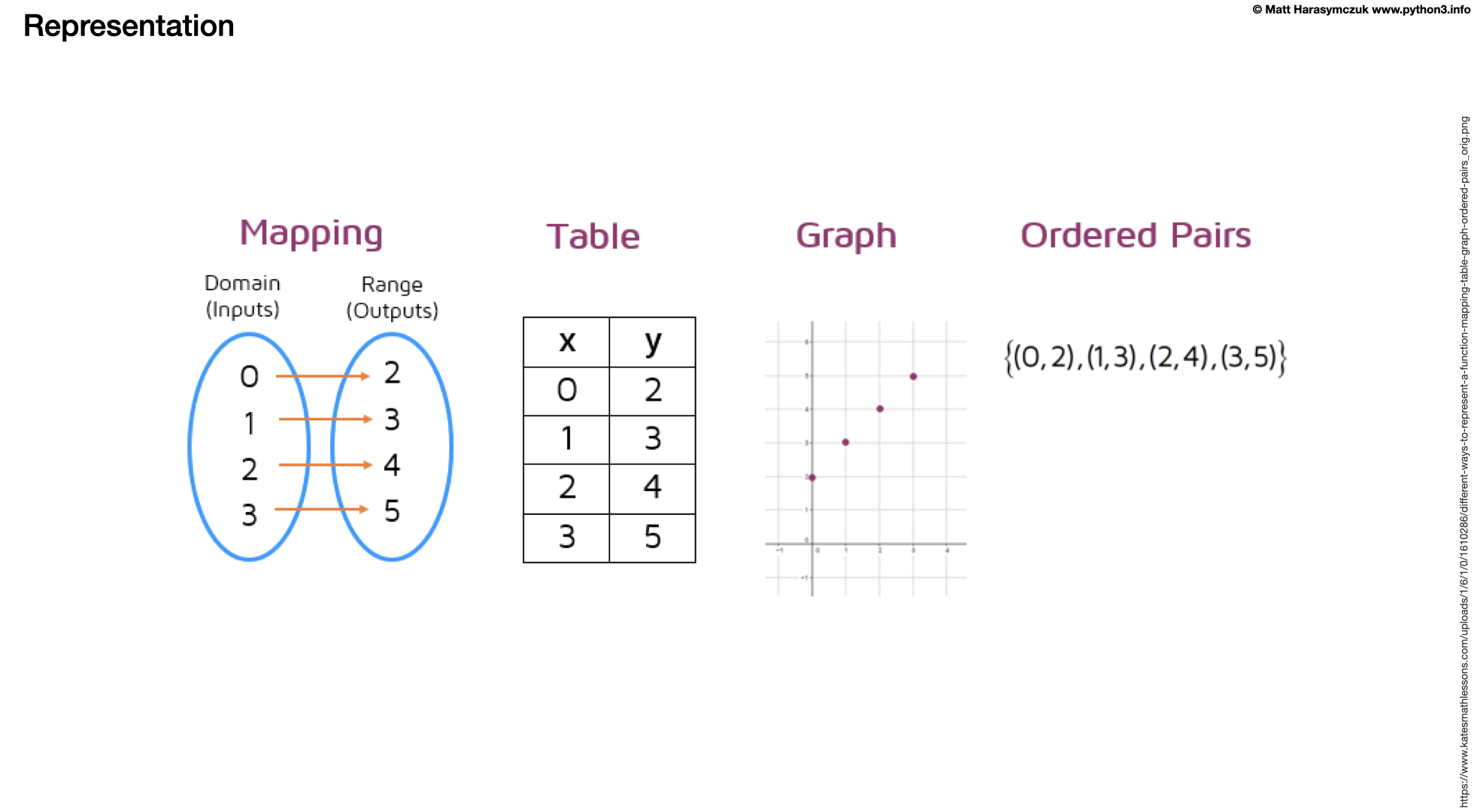
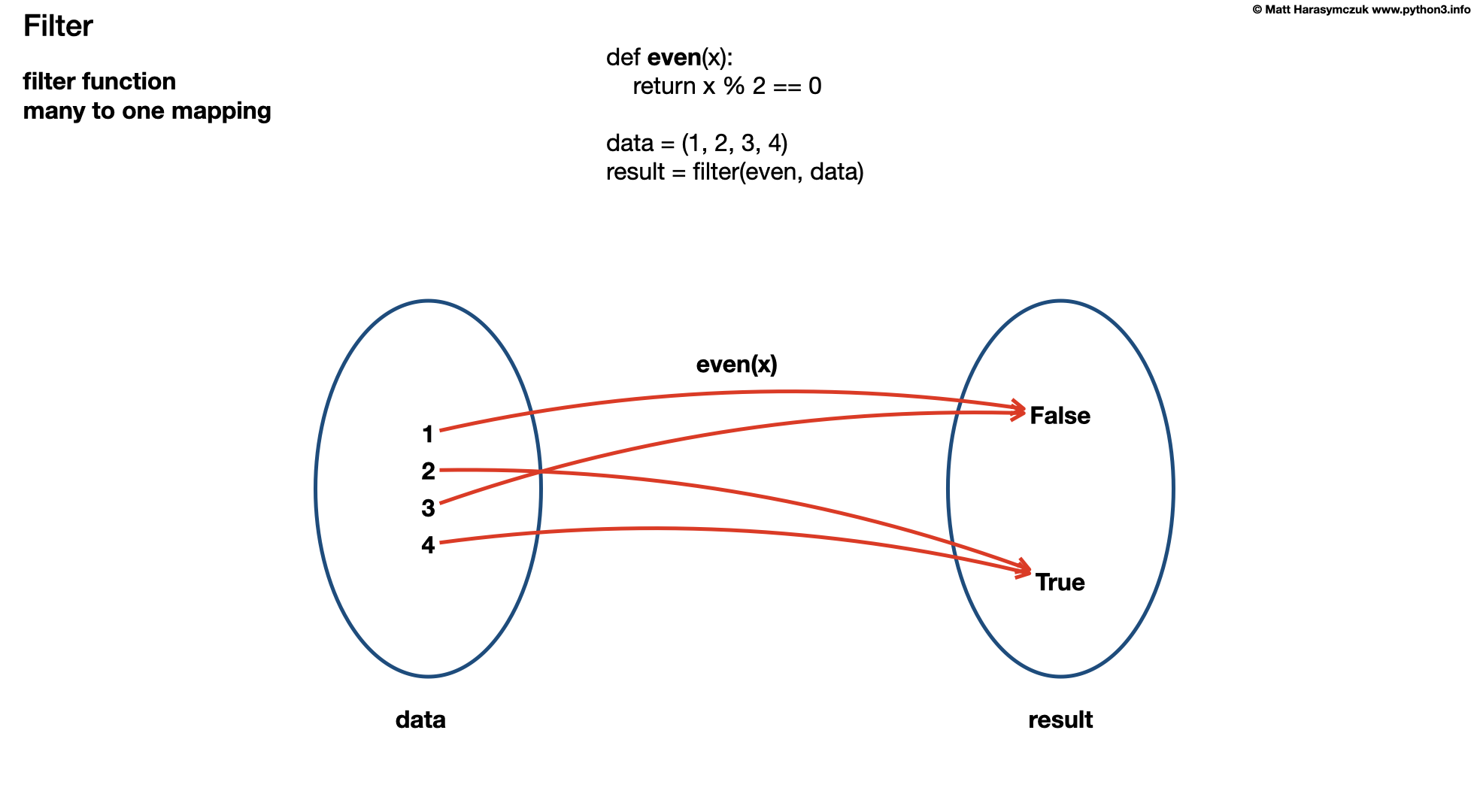
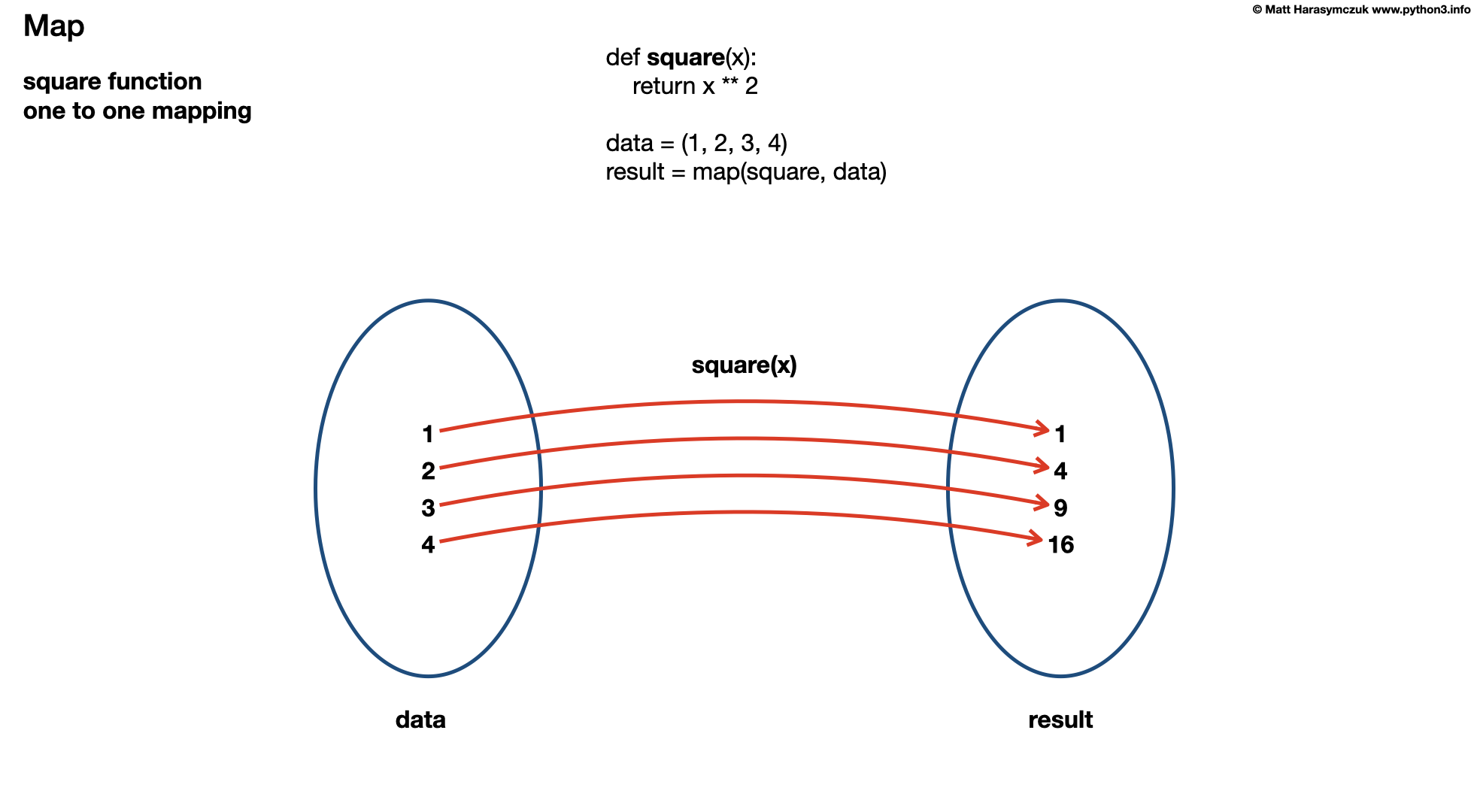
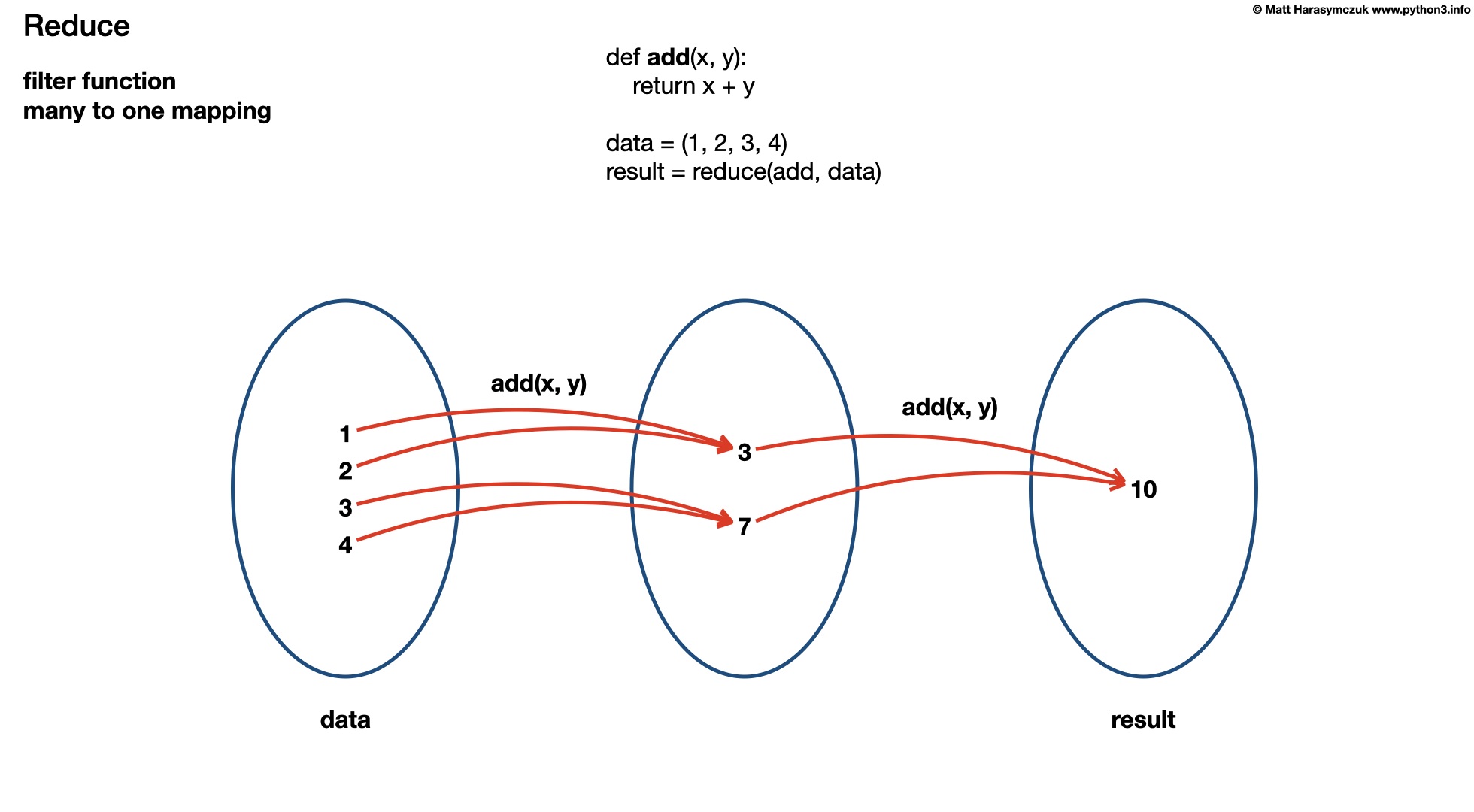
10.5.2. Assignments
# %% About
# - Name: Functional Recap Json2Dataclass
# - Difficulty: medium
# - Lines: 7
# - Minutes: 8
# %% License
# - Copyright 2025, Matt Harasymczuk <matt@python3.info>
# - This code can be used only for learning by humans
# - This code cannot be used for teaching others
# - This code cannot be used for teaching LLMs and AI algorithms
# - This code cannot be used in commercial or proprietary products
# - This code cannot be distributed in any form
# - This code cannot be changed in any form outside of training course
# - This code cannot have its license changed
# - If you use this code in your product, you must open-source it under GPLv2
# - Exception can be granted only by the author
# %% English
# 1. In `DATA` we have two classes
# 2. Model data using classes and relations
# 3. Create instances dynamically based on `DATA`
# 4. Run doctests - all must succeed
# %% Polish
# 1. W `DATA` mamy dwie klasy
# 2. Zamodeluj problem wykorzystując klasy i relacje między nimi
# 3. Twórz instancje dynamicznie na podstawie `DATA`
# 4. Uruchom doctesty - wszystkie muszą się powieść
# %% Hints
# - `dict.get()`
# - `dict.values()`
# - `map()`
# - `starmap()`
# - `tuple()`
# %% Doctests
"""
>>> import sys; sys.tracebacklimit = 0
>>> assert sys.version_info >= (3, 9), \
'Python has an is invalid version; expected: `3.9` or newer.'
>>> from pprint import pprint
>>> result = list(result)
>>> assert type(result) is list
>>> assert all(type(user) is User for user in result)
>>> assert all(type(addr) is Address
... for user in result
... for addr in user.addresses)
>>> pprint(result, width=300)
[User(firstname='Alice', lastname='Apricot', addresses=(Address(street='2101 E NASA Pkwy', city='Houston', postcode='77058', region='Texas', country='USA'),)),
User(firstname='Bob', lastname='Blackthorn', addresses=(Address(street='', city='Kennedy Space Center', postcode='32899', region='Florida', country='USA'),)),
User(firstname='Carol', lastname='Corn', addresses=(Address(street='4800 Oak Grove Dr', city='Pasadena', postcode='91109', region='California', country='USA'), Address(street='2825 E Ave P', city='Palmdale', postcode='93550', region='California', country='USA'))),
User(firstname='Dave', lastname='Durian', addresses=(Address(street='Linder Hoehe', city='Cologne', postcode='51147', region='North Rhine-Westphalia', country='Germany'),)),
User(firstname='Eve', lastname='Elderberry', addresses=(Address(street='', city='Космодро́м Байкону́р', postcode='', region='Кызылординская область', country='Қазақстан'), Address(street='', city='Звёздный городо́к', postcode='141160', region='Московская область', country='Россия'))),
User(firstname='Mallory', lastname='Melon', addresses=())]
"""
# %% Run
# - PyCharm: right-click in the editor and `Run Doctest in ...`
# - PyCharm: keyboard shortcut `Control + Shift + F10`
# - Terminal: `python -m doctest -f -v myfile.py`
# %% Imports
from dataclasses import dataclass
from itertools import starmap
# %% Types
result: map
# %% Data
DATA = [
{"firstname": "Alice", "lastname": "Apricot", "addresses": [
{"street": "2101 E NASA Pkwy", "city": "Houston", "postcode": "77058", "region": "Texas", "country": "USA"}
]},
{"firstname": "Bob", "lastname": "Blackthorn", "addresses": [
{"street": "", "city": "Kennedy Space Center", "postcode": "32899", "region": "Florida", "country": "USA"}
]},
{"firstname": "Carol", "lastname": "Corn", "addresses": [
{"street": "4800 Oak Grove Dr", "city": "Pasadena", "postcode": "91109", "region": "California", "country": "USA"},
{"street": "2825 E Ave P", "city": "Palmdale", "postcode": "93550", "region": "California", "country": "USA"}
]},
{"firstname": "Dave", "lastname": "Durian", "addresses": [
{"street": "Linder Hoehe", "city": "Cologne", "postcode": "51147", "region": "North Rhine-Westphalia", "country": "Germany"}
]},
{"firstname": "Eve", "lastname": "Elderberry", "addresses": [
{"street": "", "city": "Космодро́м Байкону́р", "postcode": "", "region": "Кызылординская область", "country": "Қазақстан"},
{"street": "", "city": "Звёздный городо́к", "postcode": "141160", "region": "Московская область", "country": "Россия"}
]},
{"firstname": "Mallory", "lastname": "Melon", "addresses": []}
]
@dataclass
class Address:
street: str
city: str
postcode: str
region: str
country: str
@dataclass
class User:
firstname: str
lastname: str
addresses: tuple[Address, ...]
# %% Result
result = ...
# %% About
# - Name: Functional Recap Json2Csv
# - Difficulty: medium
# - Lines: 10
# - Minutes: 13
# %% License
# - Copyright 2025, Matt Harasymczuk <matt@python3.info>
# - This code can be used only for learning by humans
# - This code cannot be used for teaching others
# - This code cannot be used for teaching LLMs and AI algorithms
# - This code cannot be used in commercial or proprietary products
# - This code cannot be distributed in any form
# - This code cannot be changed in any form outside of training course
# - This code cannot have its license changed
# - If you use this code in your product, you must open-source it under GPLv2
# - Exception can be granted only by the author
# %% English
# 1. Write data with relations to CSV format
# 2. Convert `DATA` to `result: list[dict[str,str]]`
# 3. Non-functional requirements:
# - Use `,` to separate fields
# - Use `;` to separate instances
# 4. Contact has zero or many addresses
# 5. Run doctests - all must succeed
# %% Polish
# 1. Zapisz dane relacyjne do formatu CSV
# 2. Przekonwertuj `DATA` do `result: list[dict[str,str]]`
# 3. Wymagania niefunkcjonalne:
# - Użyj `,` do oddzielenia pól
# - Użyj `;` do oddzielenia instancji
# 4. Kontakt ma zero lub wiele adresów
# 5. Uruchom doctesty - wszystkie muszą się powieść
# %% Hints
# - `map()`
# - `dict()`
# - `dict.values()`
# - `dict.get()`
# - `str.join()`
# %% Doctests
"""
>>> import sys; sys.tracebacklimit = 0
>>> assert sys.version_info >= (3, 9), \
'Python has an is invalid version; expected: `3.9` or newer.'
>>> from pprint import pprint
>>> result = list(result)
>>> assert type(result) is list
>>> assert len(result) > 0
>>> assert all(type(x) is dict for x in result)
>>> pprint(result, width=200, sort_dicts=False)
[{'firstname': 'Alice', 'lastname': 'Apricot', 'addresses': '2101 E NASA Pkwy,Houston,77058,Texas,USA'},
{'firstname': 'Bob', 'lastname': 'Blackthorn', 'addresses': ',Kennedy Space Center,32899,Florida,USA'},
{'firstname': 'Carol', 'lastname': 'Corn', 'addresses': '4800 Oak Grove Dr,Pasadena,91109,California,USA;2825 E Ave P,Palmdale,93550,California,USA'},
{'firstname': 'Dave', 'lastname': 'Durian', 'addresses': 'Linder Hoehe,Cologne,51147,North Rhine-Westphalia,Germany'},
{'firstname': 'Eve', 'lastname': 'Elderberry', 'addresses': ',Космодро́м Байкону́р,,Кызылординская область,Қазақстан;,Звёздный городо́к,141160,Московская область,Россия'},
{'firstname': 'Mallory', 'lastname': 'Melon', 'addresses': ''}]
"""
# %% Run
# - PyCharm: right-click in the editor and `Run Doctest in ...`
# - PyCharm: keyboard shortcut `Control + Shift + F10`
# - Terminal: `python -m doctest -f -v myfile.py`
# %% Imports
# %% Types
result: map
# %% Data
DATA = [
{"firstname": "Alice", "lastname": "Apricot", "addresses": [
{"street": "2101 E NASA Pkwy", "city": "Houston", "postcode": "77058", "region": "Texas", "country": "USA"}
]},
{"firstname": "Bob", "lastname": "Blackthorn", "addresses": [
{"street": "", "city": "Kennedy Space Center", "postcode": "32899", "region": "Florida", "country": "USA"}
]},
{"firstname": "Carol", "lastname": "Corn", "addresses": [
{"street": "4800 Oak Grove Dr", "city": "Pasadena", "postcode": "91109", "region": "California", "country": "USA"},
{"street": "2825 E Ave P", "city": "Palmdale", "postcode": "93550", "region": "California", "country": "USA"}
]},
{"firstname": "Dave", "lastname": "Durian", "addresses": [
{"street": "Linder Hoehe", "city": "Cologne", "postcode": "51147", "region": "North Rhine-Westphalia", "country": "Germany"}
]},
{"firstname": "Eve", "lastname": "Elderberry", "addresses": [
{"street": "", "city": "Космодро́м Байкону́р", "postcode": "", "region": "Кызылординская область", "country": "Қазақстан"},
{"street": "", "city": "Звёздный городо́к", "postcode": "141160", "region": "Московская область", "country": "Россия"}
]},
{"firstname": "Mallory", "lastname": "Melon", "addresses": []}
]
# %% Result
result = ...
# %% About
# - Name: Functional Recap FlattenDicts
# - Difficulty: hard
# - Lines: 13
# - Minutes: 13
# %% License
# - Copyright 2025, Matt Harasymczuk <matt@python3.info>
# - This code can be used only for learning by humans
# - This code cannot be used for teaching others
# - This code cannot be used for teaching LLMs and AI algorithms
# - This code cannot be used in commercial or proprietary products
# - This code cannot be distributed in any form
# - This code cannot be changed in any form outside of training course
# - This code cannot have its license changed
# - If you use this code in your product, you must open-source it under GPLv2
# - Exception can be granted only by the author
# %% English
# 1. Convert `DATA` to format with one column per each attribute for example:
# - `group1_gid`, `group2_gid`,
# - `group1_name`, `group2_name`
# 2. Note, that enumeration starts with one
# 3. Collect data to `result: map`
# 4. Run doctests - all must succeed
# %% Polish
# 1. Przekonwertuj `DATA` do formatu z jedną kolumną dla każdego atrybutu, np:
# - `group1_gid`, `group2_gid`,
# - `group1_name`, `group2_name`
# 2. Zwróć uwagę, że enumeracja zaczyna się od jeden
# 3. Zbierz dane do `result: map`
# 4. Uruchom doctesty - wszystkie muszą się powieść
# %% Expected
# >>> result
# [{'firstname': 'Alice',
# 'lastname': 'Apricot',
# 'group1_gid': 1,
# 'group1_name': 'users',
# 'group2_gid': 2,
# 'group2_name': 'staff'},
# {'firstname': 'Bob',
# 'lastname': 'Blackthorn',
# 'group1_gid': 1,
# 'group1_name': 'users',
# 'group2_gid': 2,
# 'group2_name': 'staff'},
# {'firstname': 'Carol',
# 'lastname': 'Corn',
# 'group1_gid': 1,
# 'group1_name': 'users'},
# {'firstname': 'Dave',
# 'lastname': 'Durian',
# 'group1_gid': 1,
# 'group1_name': 'users'},
# {'firstname': 'Eve',
# 'lastname': 'Elderberry',
# 'group1_gid': 1,
# 'group1_name': 'users',
# 'group2_gid': 2,
# 'group2_name': 'staff',
# 'group3_gid': 3,
# 'group3_name': 'admins'},
# {'firstname': 'Mallory',
# 'lastname': 'Melon'}]
# %% Hints
# - `itertools.starmap()`
# - `functools.reduce()`
# - `operator.or_`
# - `dict.get()`
# - `enumerate(iterable, start)`
# - `reduce(func, iterable, {})`
# - `dict | dict`
# - `map()`
# %% Doctests
"""
>>> import sys; sys.tracebacklimit = 0
>>> assert sys.version_info >= (3, 9), \
'Python has an is invalid version; expected: `3.9` or newer.'
>>> from pprint import pprint
>>> result = list(result)
>>> assert type(result) is list
>>> assert len(result) > 0
>>> assert all(type(x) is dict for x in result)
>>> pprint(result, width=30, sort_dicts=False)
[{'firstname': 'Alice',
'lastname': 'Apricot',
'group1_gid': 1,
'group1_name': 'users',
'group2_gid': 2,
'group2_name': 'staff'},
{'firstname': 'Bob',
'lastname': 'Blackthorn',
'group1_gid': 1,
'group1_name': 'users',
'group2_gid': 2,
'group2_name': 'staff'},
{'firstname': 'Carol',
'lastname': 'Corn',
'group1_gid': 1,
'group1_name': 'users'},
{'firstname': 'Dave',
'lastname': 'Durian',
'group1_gid': 1,
'group1_name': 'users'},
{'firstname': 'Eve',
'lastname': 'Elderberry',
'group1_gid': 1,
'group1_name': 'users',
'group2_gid': 2,
'group2_name': 'staff',
'group3_gid': 3,
'group3_name': 'admins'},
{'firstname': 'Mallory',
'lastname': 'Melon'}]
"""
# %% Run
# - PyCharm: right-click in the editor and `Run Doctest in ...`
# - PyCharm: keyboard shortcut `Control + Shift + F10`
# - Terminal: `python -m doctest -f -v myfile.py`
# %% Imports
from itertools import starmap
from functools import reduce
from operator import or_
# %% Types
result: map
# %% Data
DATA = [
{"firstname": "Alice", "lastname": "Apricot", "groups": [
{"gid": 1, "name": "users"},
{"gid": 2, "name": "staff"},
]},
{"firstname": "Bob", "lastname": "Blackthorn", "groups": [
{"gid": 1, "name": "users"},
{"gid": 2, "name": "staff"},
]},
{"firstname": "Carol", "lastname": "Corn", "groups": [
{"gid": 1, "name": "users"},
]},
{"firstname": "Dave", "lastname": "Durian", "groups": [
{"gid": 1, "name": "users"},
]},
{"firstname": "Eve", "lastname": "Elderberry", "groups": [
{"gid": 1, "name": "users"},
{"gid": 2, "name": "staff"},
{"gid": 3, "name": "admins"},
]},
{"firstname": "Mallory", "lastname": "Melon", "groups": []},
]
# %% Result
result = ...
# %% About
# - Name: Functional Recap FlattenClasses
# - Difficulty: hard
# - Lines: 15
# - Minutes: 13
# %% License
# - Copyright 2025, Matt Harasymczuk <matt@python3.info>
# - This code can be used only for learning by humans
# - This code cannot be used for teaching others
# - This code cannot be used for teaching LLMs and AI algorithms
# - This code cannot be used in commercial or proprietary products
# - This code cannot be distributed in any form
# - This code cannot be changed in any form outside of training course
# - This code cannot have its license changed
# - If you use this code in your product, you must open-source it under GPLv2
# - Exception can be granted only by the author
# %% English
# 1. Convert `DATA` to format with one column per each attribute for example:
# - `Group1_year`, `Group2_year`,
# - `Group1_name`, `Group2_name`
# 2. Note, that enumeration starts with one
# 3. Run doctests - all must succeed
# %% Polish
# 1. Przekonwertuj `DATA` do formatu z jedną kolumną dla każdego atrybutu, np:
# - `Group1_year`, `Group2_year`,
# - `Group1_name`, `Group2_name`
# 2. Zwróć uwagę, że enumeracja zaczyna się od jeden
# 3. Uruchom doctesty - wszystkie muszą się powieść
# %% Hints
# - `vars(obj)` -> `dict`
# %% Doctests
"""
>>> import sys; sys.tracebacklimit = 0
>>> assert sys.version_info >= (3, 9), \
'Python has an is invalid version; expected: `3.9` or newer.'
>>> from pprint import pprint
>>> result = list(result)
>>> assert type(result) is list
>>> assert len(result) > 0
>>> assert all(type(x) is dict for x in result)
>>> pprint(result, width=30, sort_dicts=False)
[{'firstname': 'Alice',
'lastname': 'Apricot',
'group1_gid': 1,
'group1_name': 'staff'},
{'firstname': 'Bob',
'lastname': 'Blackthorn',
'group1_gid': 1,
'group1_name': 'staff',
'group2_gid': 2,
'group2_name': 'admins'},
{'firstname': 'Carol',
'lastname': 'Corn'}]
"""
# %% Run
# - PyCharm: right-click in the editor and `Run Doctest in ...`
# - PyCharm: keyboard shortcut `Control + Shift + F10`
# - Terminal: `python -m doctest -f -v myfile.py`
# %% Imports
from itertools import starmap
from functools import reduce
from operator import or_
# %% Types
result: map
# %% Data
class User:
def __init__(self, firstname, lastname, groups=()):
self.firstname = firstname
self.lastname = lastname
self.groups = list(groups)
class Group:
def __init__(self, gid, name):
self.gid = gid
self.name = name
DATA = [
User('Alice', 'Apricot', groups=[
Group(gid=1, name='staff')]),
User('Bob', 'Blackthorn', groups=[
Group(gid=1, name='staff'),
Group(gid=2, name='admins')]),
User('Carol', 'Corn'),
]
# %% Result
def flat(i, groupobj):
group = groupobj
gid = group.get('gid')
name = group.get('name')
return {f'group{i}_gid': gid, f'group{i}_name': name}
def flatten(groups):
dicts = starmap(flat, enumerate(groups, start=1))
return reduce(or_, dicts, {})
def convert(userobj):
user = userobj
firstname = user.get('firstname')
lastname = user.get('lastname')
groups = flatten(user.get('groups'))
return {'firstname': firstname, 'lastname': lastname} | groups
result = map(convert, DATA)
# %% About
# - Name: Iterator Reduce Impl
# - Difficulty: medium
# - Lines: 5
# - Minutes: 13
# %% License
# - Copyright 2025, Matt Harasymczuk <matt@python3.info>
# - This code can be used only for learning by humans
# - This code cannot be used for teaching others
# - This code cannot be used for teaching LLMs and AI algorithms
# - This code cannot be used in commercial or proprietary products
# - This code cannot be distributed in any form
# - This code cannot be changed in any form outside of training course
# - This code cannot have its license changed
# - If you use this code in your product, you must open-source it under GPLv2
# - Exception can be granted only by the author
# %% English
# 1. Write own implementation of a built-in `reduce()` function
# 2. Define function `myreduce` with parameters:
# - parameter `function: Callable`
# - parameter `iterable: list | tuple`
# 3. Don't validate arguments and assume, that user will:
# - always pass valid type of arguments
# - iterable length will always be greater than 0
# 4. Do not use: map, filter, zip, enumerate, all, any, reduce
# 5. Run doctests - all must succeed
# %% Polish
# 1. Zaimplementuj własne rozwiązanie wbudowanej funkcji `reduce()`
# 2. Zdefiniuj funkcję `myreduce` z parametrami:
# - parameter `function: Callable`
# - parameter `iterable: list | tuple`
# 3. Nie waliduj argumentów i przyjmij, że użytkownik:
# - zawsze poda argumenty poprawnych typów
# - długość iterable będzie większa od 0
# 4. Nie używaj: map, filter, zip, enumerate, all, any, reduce
# 5. Uruchom doctesty - wszystkie muszą się powieść
# %% Doctests
"""
>>> import sys; sys.tracebacklimit = 0
>>> assert sys.version_info >= (3, 9), \
'Python has an is invalid version; expected: `3.9` or newer.'
>>> from inspect import isfunction
>>> from operator import add, mul
>>> assert isfunction(myreduce)
>>> myreduce(add, [1, 2, 3, 4, 5])
15
>>> myreduce(mul, [1, 2, 3, 4, 5])
120
"""
# %% Run
# - PyCharm: right-click in the editor and `Run Doctest in ...`
# - PyCharm: keyboard shortcut `Control + Shift + F10`
# - Terminal: `python -m doctest -f -v myfile.py`
# %% Imports
# %% Types
from typing import Callable
myreduce: Callable[[Callable, tuple|list], object]
# %% Data
# %% Result
def myreduce(function, iterable):
...