12.1. FP Apply Map
Converts elements in sequence
Lazy evaluated
map(callable, *iterables)required
callable- Functionrequired
iterables- 1 or many sequence or iterator objects
The map() function in Python is a built-in function that applies a given
function to each element of an iterable (such as a list, tuple, or set) and
returns a new iterable with the results. It takes two arguments: a function
and an iterable.
The function is applied to each element in the iterable, and the results are collected into a new iterable. The resulting iterable can be converted to a list, tuple, or set if desired.
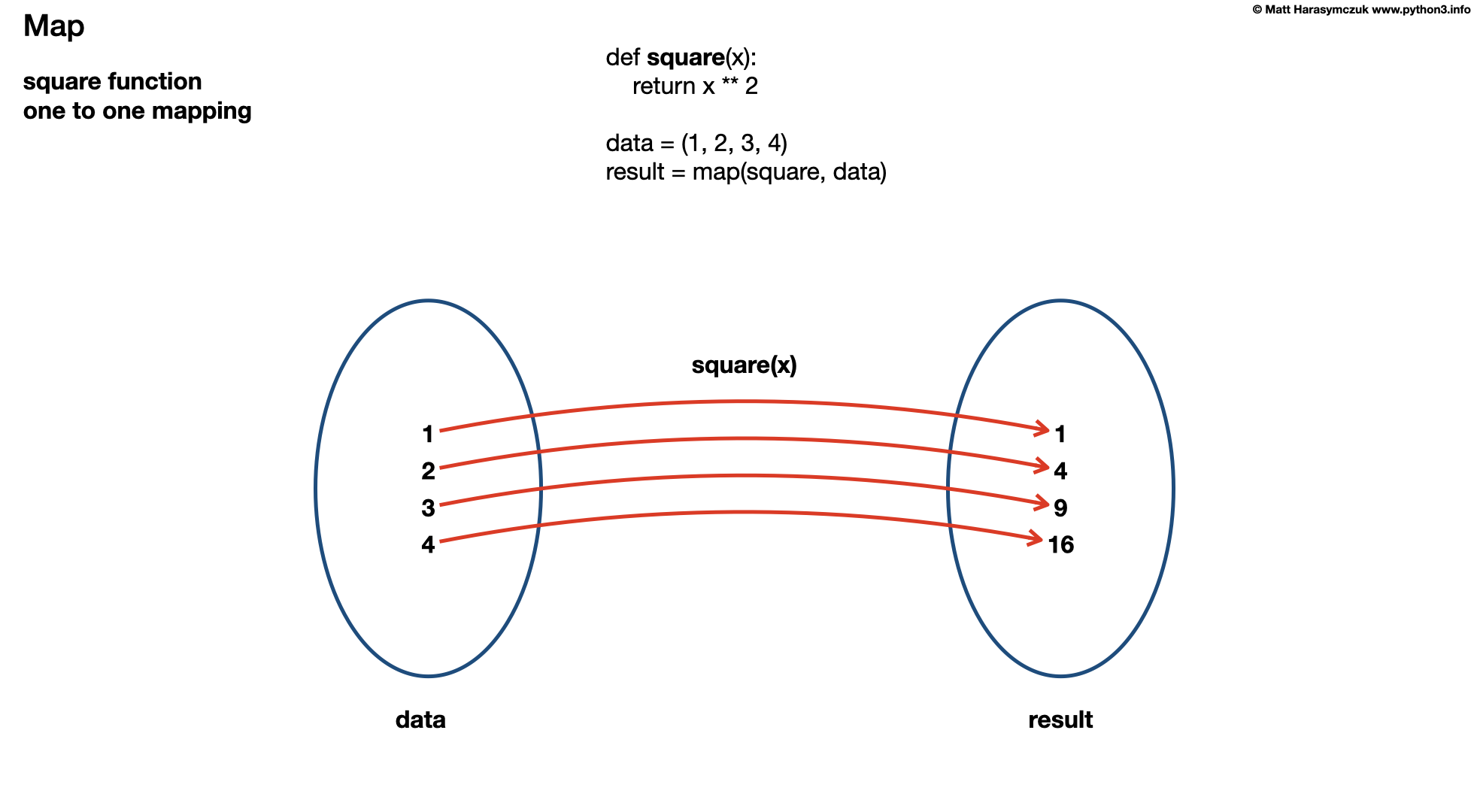
12.1.1. Example
Here's an example of using the map() function to square each number
in a list:
>>> def square(n):
... return n ** 2
>>>
>>> data = (1, 2, 3, 4, 5)
>>> result = map(square, data)
>>> tuple(result)
(1, 4, 9, 16, 25)
In this example, the power function is applied to each element in the
numbers list using the map() function. The resulting iterable contains
the squared values of each element in the original tuple. The tuple()
function is used to convert the iterable to a tuple.
12.1.2. Problem
>>> def square(x):
... return x ** 2
>>>
>>> data = (1, 2, 3, 4)
>>>
>>> result = [square(x) for x in data]
>>> tuple(result)
(1, 4, 9, 16)
12.1.3. Solution
>>> def square(x):
... return x ** 2
>>>
>>> data = (1, 2, 3, 4)
>>>
>>> result = map(square, data)
>>> tuple(result)
(1, 4, 9, 16)
12.1.4. Lazy Evaluation
>>> def square(x):
... return x ** 2
>>>
>>> data = (1, 2, 3, 4)
Usage:
>>> result = map(square, data)
>>>
>>> next(result)
1
>>>
>>> next(result)
4
>>>
>>> next(result)
9
>>>
>>> next(result)
16
>>>
>>> next(result)
Traceback (most recent call last):
StopIteration
12.1.5. Iteration
>>> def square(x):
... return x ** 2
>>>
>>> data = (1, 2, 3, 4)
>>>
>>> for result in map(square, data):
... print(result)
1
4
9
16
12.1.6. Multiple Arguments
>>> def power(num, exp):
... return num ** exp
...
>>> numbers = (1, 2, 3, 4)
>>> exponents = (2, 3, 4, 5)
>>>
>>> result = map(power, numbers, exponents)
>>>
>>> tuple(result)
(1, 8, 81, 1024)
12.1.7. Starmap
>>> from itertools import starmap
>>> def power(num, exp):
... return num ** exp
>>>
>>> data = (
... (1, 2),
... (2, 3),
... (3, 4),
... (4, 5),
... )
>>>
>>> result = starmap(power, data)
>>> tuple(result)
(1, 8, 81, 1024)
Map behind the scenes:
>>> map(pow, data)
<map object at 0x1059f62c0>
# add( data[0] ) # add( (1,2) )
# add( data[1] ) # add( (3,4) )
# add( data[2] ) # add( (5,6) )
Starmap behind the scenes:
>>> starmap(pow, data)
<itertools.starmap object at 0x105b19090>
# add( *data[0] ) # add( *(1,2) ) # add(1, 2)
# add( *data[1] ) # add( *(3,4) ) # add(3, 4)
# add( *data[2] ) # add( *(5,6) ) # add(5, 6)
12.1.8. Not A Generator
from inspect import isgeneratorfunction, isgeneratorisgeneratorfunction(callable)- Check if the object is a generator functionisgenerator(iterator)- Check if the object is a generator iteratormap()is not a generator function
SetUp:
>>> from inspect import isgeneratorfunction, isgenerator
Map function:
>>> isgeneratorfunction(map)
False
Map object:
>>> data = (1, 2, 3, 4)
>>> result = map(float, data)
>>>
>>> isgenerator(result)
False
12.1.9. Performance
Date: 2024-12-01
Python: 3.13.0
IPython: 8.30.0
System: macOS 15.1.1
Computer: MacBook M3 Max
CPU: 16 cores (12 performance and 4 efficiency) / 3nm
RAM: 128 GB RAM LPDDR5
>>> def power(x, exp):
... return x ** exp
...
>>> data = (1, 2, 3, 4)
>>> ## doctest: +SKIP
... %%timeit -n 1000 -r 1000
... result = [square(x) for x in data]
...
328 ns ± 58.1 ns per loop (mean ± std. dev. of 1000 runs, 1,000 loops each)
329 ns ± 54.6 ns per loop (mean ± std. dev. of 1000 runs, 1,000 loops each)
337 ns ± 54.8 ns per loop (mean ± std. dev. of 1000 runs, 1,000 loops each)
>>> ## doctest: +SKIP
... %%timeit -n 1000 -r 1000
... result = list(square(x) for x in data)
...
474 ns ± 65.2 ns per loop (mean ± std. dev. of 1000 runs, 1,000 loops each)
479 ns ± 70.8 ns per loop (mean ± std. dev. of 1000 runs, 1,000 loops each)
473 ns ± 51.2 ns per loop (mean ± std. dev. of 1000 runs, 1,000 loops each)
>>> ## doctest: +SKIP
... %%timeit -n 1000 -r 1000
... result = list(map(square, data))
...
390 ns ± 60.5 ns per loop (mean ± std. dev. of 1000 runs, 1,000 loops each)
381 ns ± 57.8 ns per loop (mean ± std. dev. of 1000 runs, 1,000 loops each)
386 ns ± 62.7 ns per loop (mean ± std. dev. of 1000 runs, 1,000 loops each)
>>> ## doctest: +SKIP
... %%timeit -n 1000 -r 1000
... result = (square(x) for x in data)
...
91.1 ns ± 20.4 ns per loop (mean ± std. dev. of 1000 runs, 1,000 loops each)
91.1 ns ± 21.8 ns per loop (mean ± std. dev. of 1000 runs, 1,000 loops each)
88.6 ns ± 20 ns per loop (mean ± std. dev. of 1000 runs, 1,000 loops each)
>>> ## doctest: +SKIP
... %%timeit -n 1000 -r 1000
... result = map(square, data)
...
56.6 ns ± 14 ns per loop (mean ± std. dev. of 1000 runs, 1,000 loops each)
54.5 ns ± 10.1 ns per loop (mean ± std. dev. of 1000 runs, 1,000 loops each)
57.1 ns ± 12.7 ns per loop (mean ± std. dev. of 1000 runs, 1,000 loops each)
12.1.10. Use Case - 1
>>> data = (1, 2, 3, 4)
>>> result = map(float, data)
>>>
>>> tuple(result)
(1.0, 2.0, 3.0, 4.0)
12.1.11. Use Case - 2
>>> def increment(x):
... return x + 1
>>>
>>>
>>> data = (1, 2, 3, 4)
>>> result = map(increment, data)
>>>
>>> tuple(result)
(2, 3, 4, 5)
12.1.12. Use Case - 3
>>> def upper(x):
... return x.upper()
>>>
>>> data = ('a', 'b', 'c')
>>> result = map(upper, data)
>>>
>>> tuple(result)
('A', 'B', 'C')
12.1.13. Use Case - 4
SetUp:
>>> data = (1, 2, 3, 4)
Output formats:
>>> result = map(float, data)
>>> tuple(result)
(1.0, 2.0, 3.0, 4.0)
>>> result = map(float, data)
>>> set(result)
{1.0, 2.0, 3.0, 4.0}
>>> result = map(float, data)
>>> list(result)
[1.0, 2.0, 3.0, 4.0]
12.1.14. Use Case - 5
>>> def translate(letter):
... return PL.get(letter, letter)
>>>
>>> PL = {'ą': 'a', 'ć': 'c', 'ę': 'e',
... 'ł': 'l', 'ń': 'n', 'ó': 'o',
... 'ś': 's', 'ż': 'z', 'ź': 'z'}
>>>
>>> data = 'zażółć gęślą jaźń'
>>> result = map(translate, data)
>>> ''.join(result)
'zazolc gesla jazn'
12.1.15. Use Case - 6
Standard input:
>>> import sys
>>>
>>> #
... print(sum(map(int, sys.stdin)))
$ cat ~/.profile |grep addnum
alias addnum='python -c"import sys; print(sum(map(int, sys.stdin)))"'
12.1.16. Use Case - 7
>>> from dataclasses import dataclass
>>> from pprint import pprint
>>>
>>>
>>> DATA = [
... ('sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species'),
... (5.8, 2.7, 5.1, 1.9, 'virginica'),
... (5.1, 3.5, 1.4, 0.2, 'setosa'),
... (5.7, 2.8, 4.1, 1.3, 'versicolor'),
... (6.3, 2.9, 5.6, 1.8, 'virginica'),
... (6.4, 3.2, 4.5, 1.5, 'versicolor'),
... (4.7, 3.2, 1.3, 0.2, 'setosa'),
... (7.0, 3.2, 4.7, 1.4, 'versicolor'),
... (7.6, 3.0, 6.6, 2.1, 'virginica'),
... (4.6, 3.1, 1.5, 0.2, 'setosa'),
... ]
>>>
>>> header, *rows = DATA
>>>
>>> @dataclass
... class Iris:
... sl: float
... sw: float
... pl: float
... pw: float
... species: str
...
>>>
>>> result = starmap(Iris, rows)
>>> pprint(tuple(result))
(Iris(sl=5.8, sw=2.7, pl=5.1, pw=1.9, species='virginica'),
Iris(sl=5.1, sw=3.5, pl=1.4, pw=0.2, species='setosa'),
Iris(sl=5.7, sw=2.8, pl=4.1, pw=1.3, species='versicolor'),
Iris(sl=6.3, sw=2.9, pl=5.6, pw=1.8, species='virginica'),
Iris(sl=6.4, sw=3.2, pl=4.5, pw=1.5, species='versicolor'),
Iris(sl=4.7, sw=3.2, pl=1.3, pw=0.2, species='setosa'),
Iris(sl=7.0, sw=3.2, pl=4.7, pw=1.4, species='versicolor'),
Iris(sl=7.6, sw=3.0, pl=6.6, pw=2.1, species='virginica'),
Iris(sl=4.6, sw=3.1, pl=1.5, pw=0.2, species='setosa'))
Map behind the scenes:
>>> map(Iris, rows)
<map object at 0x1034f5b10>
# Iris(rows[0])
# Iris(rows[1])
# Iris(rows[2])
# ...
# Iris(rows[9])
Starmap behind the scenes:
>>> starmap(Iris, rows)
<itertools.starmap object at 0x103529d80>
# Iris(*rows[0])
# Iris(*rows[1])
# Iris(*rows[2])
# ...
# Iris(*rows[9])
12.1.17. Use Case - 8
>>> import httpx
>>>
>>> url = 'https://python3.info/_static/iris-dirty.csv'
>>>
>>> data = httpx.get(url).text
>>> header, *rows = data.splitlines()
>>> nrows, nfeatures, *class_labels = header.strip().split(',')
>>> label_encoder = dict(enumerate(class_labels))
Procedural:
>>> result = []
>>> for row in rows:
... *features, species = row.strip().split(',')
... features = map(float, features)
... species = label_encoder[int(species)]
... row = tuple(features) + (species,)
... result.append(row)
Functional:
>>> def decode(row):
... *features, species = row.strip().split(',')
... features = map(float, features)
... species = label_encoder[int(species)]
... return tuple(features) + (species,)
>>>
>>> result = map(decode, rows)
Mixed:
>>> def decode(row):
... *features, species = row.strip().split(',')
... features = map(float, features)
... species = label_encoder[int(species)]
... return tuple(features) + (species,)
>>>
>>> with open('/tmp/myfile.csv') as file:
... header = file.readline()
... for line in map(decode, file):
... print(line)
12.1.18. Use Case - 8
SetUp:
>>> from doctest import testmod as run_tests
Data [1]:
>>> DATA = """150,4,setosa,versicolor,virginica
... 5.1,3.5,1.4,0.2,0
... 7.0,3.2,4.7,1.4,1
... 6.3,3.3,6.0,2.5,2
... 4.9,3.0,1.4,0.2,0
... 6.4,3.2,4.5,1.5,1
... 5.8,2.7,5.1,1.9,2"""
Definition:
>>> def get_labelencoder(header: str) -> dict[int, str]:
... """
... >>> get_labelencoder('150,4,setosa,versicolor,virginica')
... {0: 'setosa', 1: 'versicolor', 2: 'virginica'}
... """
... nrows, nfeatures, *class_labels = header.split(',')
... return dict(enumerate(class_labels))
>>>
>>> run_tests()
TestResults(failed=0, attempted=1)
>>> def get_data(line: str) -> tuple:
... """
... >>> convert('5.1,3.5,1.4,0.2,0')
... (5.1, 3.5, 1.4, 0.2, 'setosa')
... >>> convert('7.0,3.2,4.7,1.4,1')
... (7.0, 3.2, 4.7, 1.4, 'versicolor')
... >>> convert('6.3,3.3,6.0,2.5,2')
... (6.3, 3.3, 6.0, 2.5, 'virginica')
... """
... *values, species = line.split(',')
... values = map(float, values)
... species = label_encoder[int(species)]
... return tuple(values) + (species,)
>>>
>>> run_tests()
TestResults(failed=0, attempted=3)
>>> header, *lines = DATA.splitlines()
>>> label_encoder = get_labelencoder(header)
>>> result = map(get_data, lines)
>>> list(result)
[(5.1, 3.5, 1.4, 0.2, 'setosa'),
(7.0, 3.2, 4.7, 1.4, 'versicolor'),
(6.3, 3.3, 6.0, 2.5, 'virginica'),
(4.9, 3.0, 1.4, 0.2, 'setosa'),
(6.4, 3.2, 4.5, 1.5, 'versicolor'),
(5.8, 2.7, 5.1, 1.9, 'virginica')]
12.1.19. References
12.1.20. Assignments
# %% About
# - Name: Functional Map Float
# - Difficulty: easy
# - Lines: 1
# - Minutes: 2
# %% License
# - Copyright 2025, Matt Harasymczuk <matt@python3.info>
# - This code can be used only for learning by humans
# - This code cannot be used for teaching others
# - This code cannot be used for teaching LLMs and AI algorithms
# - This code cannot be used in commercial or proprietary products
# - This code cannot be distributed in any form
# - This code cannot be changed in any form outside of training course
# - This code cannot have its license changed
# - If you use this code in your product, you must open-source it under GPLv2
# - Exception can be granted only by the author
# %% English
# 1. Define `result: map` with values from `DATA` converted to float
# 2. Use `map()`
# 3. Run doctests - all must succeed
# %% Polish
# 1. Zdefiniuj `result: map` z wartościami z `DATA` przekonwertowanymi na float
# 2. Użyj `map()`
# 3. Uruchom doctesty - wszystkie muszą się powieść
# %% Expected
# >>> result
# (1.0, 2.0, 3.0, 4.0, 5.0)
# %% Hints
# - `map()`
# - `float()`
# %% Doctests
"""
>>> import sys; sys.tracebacklimit = 0
>>> assert sys.version_info >= (3, 9), \
'Python has an is invalid version; expected: `3.9` or newer.'
>>> from inspect import isfunction
>>> assert 'result' in globals(), \
'Variable `result` is not defined; assign result of your program to it.'
>>> assert result is not Ellipsis, \
'Variable `result` has an invalid value; assign result of your program to it.'
>>> assert type(result) is map, \
'Variable `result` has an invalid type; expected: `map`.'
>>> result = tuple(result)
>>> assert all(type(x) is float for x in result), \
'Variable `result` has elements of an invalid type; all items should be: `float`.'
>>> from pprint import pprint
>>> pprint(result, width=72, sort_dicts=False)
(1.0, 2.0, 3.0, 4.0, 5.0)
"""
# %% Run
# - PyCharm: right-click in the editor and `Run Doctest in ...`
# - PyCharm: keyboard shortcut `Control + Shift + F10`
# - Terminal: `python -m doctest -f -v myfile.py`
# %% Imports
# %% Types
result: map
# %% Data
DATA = (1, 2, 3, 4, 5)
# %% Result
result = ...
# %% About
# - Name: Functional Map Square
# - Difficulty: easy
# - Lines: 3
# - Minutes: 2
# %% License
# - Copyright 2025, Matt Harasymczuk <matt@python3.info>
# - This code can be used only for learning by humans
# - This code cannot be used for teaching others
# - This code cannot be used for teaching LLMs and AI algorithms
# - This code cannot be used in commercial or proprietary products
# - This code cannot be distributed in any form
# - This code cannot be changed in any form outside of training course
# - This code cannot have its license changed
# - If you use this code in your product, you must open-source it under GPLv2
# - Exception can be granted only by the author
# %% English
# 1. Define `result: map` with values from `DATA` squared (power of 2)
# 2. Use `map()`
# 3. Run doctests - all must succeed
# %% Polish
# 1. Zdefiniuj `result: map` z wartościami z `DATA` podniesionymi do kwadratu
# 2. Użyj `map()`
# 3. Uruchom doctesty - wszystkie muszą się powieść
# %% Expected
# >>> result
# (1, 4, 9, 16, 25)
# %% Hints
# - `map()`
# %% Doctests
"""
>>> import sys; sys.tracebacklimit = 0
>>> assert sys.version_info >= (3, 9), \
'Python has an is invalid version; expected: `3.9` or newer.'
>>> assert 'result' in globals(), \
'Variable `result` is not defined; assign result of your program to it.'
>>> assert result is not Ellipsis, \
'Variable `result` has an invalid value; assign result of your program to it.'
>>> assert type(result) is map, \
'Variable `result` has an invalid type; expected: `map`.'
>>> result = tuple(result)
>>> assert all(type(x) is int for x in result), \
'Variable `result` has elements of an invalid type; all items should be: `int`.'
>>> from pprint import pprint
>>> pprint(result, width=72, sort_dicts=False)
(1, 4, 9, 16, 25)
"""
# %% Run
# - PyCharm: right-click in the editor and `Run Doctest in ...`
# - PyCharm: keyboard shortcut `Control + Shift + F10`
# - Terminal: `python -m doctest -f -v myfile.py`
# %% Imports
# %% Types
result: map
# %% Data
DATA = (1, 2, 3, 4, 5)
# %% Result
result = ...
# %% About
# - Name: Functional Map Apply
# - Difficulty: easy
# - Lines: 3
# - Minutes: 2
# %% License
# - Copyright 2025, Matt Harasymczuk <matt@python3.info>
# - This code can be used only for learning by humans
# - This code cannot be used for teaching others
# - This code cannot be used for teaching LLMs and AI algorithms
# - This code cannot be used in commercial or proprietary products
# - This code cannot be distributed in any form
# - This code cannot be changed in any form outside of training course
# - This code cannot have its license changed
# - If you use this code in your product, you must open-source it under GPLv2
# - Exception can be granted only by the author
# %% English
# 1. Define `result: map` with letters from `DATA` uppercased
# 2. Define own `upper()` function for the transformation
# 3. Use `map()`
# 4. Run doctests - all must succeed
# %% Polish
# 1. Zdefiniuj `result: map` z literami z `DATA` przekonwertowanymi do dużych
# 2. Zdefiniuj własną funkcję `upper()` do transformacji
# 3. Użyj `map()`
# 4. Uruchom doctesty - wszystkie muszą się powieść
# %% Expected
# >>> result
# ('A', 'B', 'C', 'D', 'E')
# %% Hints
# - `map()`
# - `str.upper()`
# %% Doctests
"""
>>> import sys; sys.tracebacklimit = 0
>>> assert sys.version_info >= (3, 9), \
'Python has an is invalid version; expected: `3.9` or newer.'
>>> from inspect import isfunction
>>> assert isfunction(upper), \
'Object `upper` must be a function'
>>> assert 'result' in globals(), \
'Variable `result` is not defined; assign result of your program to it.'
>>> assert result is not Ellipsis, \
'Variable `result` has an invalid value; assign result of your program to it.'
>>> assert type(result) is map, \
'Variable `result` has an invalid type; expected: `map`.'
>>> result = tuple(result)
>>> assert all(type(x) is str for x in result), \
'Variable `result` has elements of an invalid type; all items should be: `str`.'
>>> from pprint import pprint
>>> pprint(result, width=72, sort_dicts=False)
('A', 'B', 'C', 'D', 'E')
"""
# %% Run
# - PyCharm: right-click in the editor and `Run Doctest in ...`
# - PyCharm: keyboard shortcut `Control + Shift + F10`
# - Terminal: `python -m doctest -f -v myfile.py`
# %% Imports
# %% Types
result: map
# %% Data
DATA = ('a', 'b', 'c', 'd', 'e')
# %% Result
result = ...
# %% About
# - Name: Functional Map Apply
# - Difficulty: easy
# - Lines: 1
# - Minutes: 2
# %% License
# - Copyright 2025, Matt Harasymczuk <matt@python3.info>
# - This code can be used only for learning by humans
# - This code cannot be used for teaching others
# - This code cannot be used for teaching LLMs and AI algorithms
# - This code cannot be used in commercial or proprietary products
# - This code cannot be distributed in any form
# - This code cannot be changed in any form outside of training course
# - This code cannot have its license changed
# - If you use this code in your product, you must open-source it under GPLv2
# - Exception can be granted only by the author
# %% English
# 1. Define `result: map` with letters from `DATA` uppercased
# 2. Do not define own function for the transformation
# 3. Use `map()`
# 4. Run doctests - all must succeed
# %% Polish
# 1. Zdefiniuj `result: map` z literami z `DATA` przekonwertowanymi do dużych
# 2. Nie definiuj własnej funkcji do transformacji
# 3. Użyj `map()`
# 4. Uruchom doctesty - wszystkie muszą się powieść
# %% Expected
# >>> result
# ('A', 'B', 'C', 'D', 'E')
# %% Hints
# - `map()`
# - `str.upper()`
# %% Doctests
"""
>>> import sys; sys.tracebacklimit = 0
>>> assert sys.version_info >= (3, 9), \
'Python has an is invalid version; expected: `3.9` or newer.'
>>> from inspect import isfunction
>>> assert 'result' in globals(), \
'Variable `result` is not defined; assign result of your program to it.'
>>> assert result is not Ellipsis, \
'Variable `result` has an invalid value; assign result of your program to it.'
>>> assert type(result) is map, \
'Variable `result` has an invalid type; expected: `map`.'
>>> result = tuple(result)
>>> assert all(type(x) is str for x in result), \
'Variable `result` has elements of an invalid type; all items should be: `str`.'
>>> from pprint import pprint
>>> pprint(result, width=72, sort_dicts=False)
('A', 'B', 'C', 'D', 'E')
"""
# %% Run
# - PyCharm: right-click in the editor and `Run Doctest in ...`
# - PyCharm: keyboard shortcut `Control + Shift + F10`
# - Terminal: `python -m doctest -f -v myfile.py`
# %% Imports
# %% Types
result: map
# %% Data
DATA = ('a', 'b', 'c', 'd', 'e')
# %% Result
result = ...
# %% About
# - Name: Functional Map FromISOFormat
# - Difficulty: easy
# - Lines: 1
# - Minutes: 2
# %% License
# - Copyright 2025, Matt Harasymczuk <matt@python3.info>
# - This code can be used only for learning by humans
# - This code cannot be used for teaching others
# - This code cannot be used for teaching LLMs and AI algorithms
# - This code cannot be used in commercial or proprietary products
# - This code cannot be distributed in any form
# - This code cannot be changed in any form outside of training course
# - This code cannot have its license changed
# - If you use this code in your product, you must open-source it under GPLv2
# - Exception can be granted only by the author
# %% English
# 1. Define `result: map` with parsed `DATA` dates
# 2. Use `map()` and `datetime.fromisoformat()`
# 3. Run doctests - all must succeed
# %% Polish
# 1. Zdefiniuj `result: map` ze sparsowanymi datami `DATA`
# 2. Użyj `map()` oraz `datetime.fromisoformat()`
# 3. Uruchom doctesty - wszystkie muszą się powieść
# %% Expected
# >>> result
# (datetime.date(1961, 4, 12), datetime.date(1969, 7, 21))
# %% Hints
# - `map()`
# - `datetime.fromisoformat()`
# %% Doctests
"""
>>> import sys; sys.tracebacklimit = 0
>>> assert sys.version_info >= (3, 9), \
'Python has an is invalid version; expected: `3.9` or newer.'
>>> assert 'result' in globals(), \
'Variable `result` is not defined; assign result of your program to it.'
>>> assert result is not Ellipsis, \
'Variable `result` has an invalid value; assign result of your program to it.'
>>> assert type(result) is map, \
'Variable `result` has an invalid type; expected: `map`.'
>>> result = tuple(result)
>>> assert all(type(x) is date for x in result), \
'Variable `result` has elements of an invalid type; all items should be: `date`.'
>>> from pprint import pprint
>>> pprint(result, width=79, sort_dicts=False)
(datetime.date(1961, 4, 12), datetime.date(1969, 7, 21))
"""
# %% Run
# - PyCharm: right-click in the editor and `Run Doctest in ...`
# - PyCharm: keyboard shortcut `Control + Shift + F10`
# - Terminal: `python -m doctest -f -v myfile.py`
# %% Imports
from datetime import date
# %% Types
result: map
# %% Data
DATA = (
'1961-04-12',
'1969-07-21',
)
# %% Result
result = ...
# %% About
# - Name: Functional Map DateFormats
# - Difficulty: easy
# - Lines: 1
# - Minutes: 3
# %% License
# - Copyright 2025, Matt Harasymczuk <matt@python3.info>
# - This code can be used only for learning by humans
# - This code cannot be used for teaching others
# - This code cannot be used for teaching LLMs and AI algorithms
# - This code cannot be used in commercial or proprietary products
# - This code cannot be distributed in any form
# - This code cannot be changed in any form outside of training course
# - This code cannot have its license changed
# - If you use this code in your product, you must open-source it under GPLv2
# - Exception can be granted only by the author
# %% English
# 1. Define `result: map` with parsed `DATA` dates
# 2. Use `map()`
# 3. Run doctests - all must succeed
# %% Polish
# 1. Zdefiniuj `result: map` ze sparsowanymi datami `DATA`
# 2. Użyj `map()`
# 3. Uruchom doctesty - wszystkie muszą się powieść
# %% Expected
# >>> result
# (datetime.datetime(1957, 10, 4, 19, 28, 34),
# datetime.datetime(1961, 4, 12, 6, 7),
# datetime.datetime(1969, 7, 21, 2, 56, 15))
# %% Hints
# - `for ... in`
# - nested `try ... except`
# - `FORMATS = []`
# - `for fmt in FORMATS`
# - helper function
# - 24-hour clock
# - `map(func, iterable1, iterable1)`
# %% Doctests
"""
>>> import sys; sys.tracebacklimit = 0
>>> assert sys.version_info >= (3, 9), \
'Python has an is invalid version; expected: `3.9` or newer.'
>>> assert 'result' in globals(), \
'Variable `result` is not defined; assign result of your program to it.'
>>> assert result is not Ellipsis, \
'Variable `result` has an invalid value; assign result of your program to it.'
>>> assert type(result) is map, \
'Variable `result` has an invalid type; expected: `map`.'
>>> result = tuple(result)
>>> assert all(type(x) is datetime for x in result), \
'Variable `result` has elements of an invalid type; all items should be: `datetime`.'
>>> result # doctest: +NORMALIZE_WHITESPACE
(datetime.datetime(1957, 10, 4, 19, 28, 34),
datetime.datetime(1961, 4, 12, 6, 7),
datetime.datetime(1969, 7, 21, 2, 56, 15))
"""
# %% Run
# - PyCharm: right-click in the editor and `Run Doctest in ...`
# - PyCharm: keyboard shortcut `Control + Shift + F10`
# - Terminal: `python -m doctest -f -v myfile.py`
# %% Imports
from datetime import datetime
# %% Types
result: map
# %% Data
DATA = [
'Oct 4, 1957 19:28:34', # Sputnik launch (first satellite in space)
'April 12, 1961 6:07', # Gagarin launch (first human in space)
'July 21, 1969 2:56:15', # Armstrong first step on the Moon
]
FORMATS = [
'%b %d, %Y %H:%M:%S',
'%B %d, %Y %H:%M',
'%B %d, %Y %H:%M:%S',
]
# %% Result
result = ...
# %% About
# - Name: Functional Map Logs
# - Difficulty: medium
# - Lines: 7
# - Minutes: 8
# %% License
# - Copyright 2025, Matt Harasymczuk <matt@python3.info>
# - This code can be used only for learning by humans
# - This code cannot be used for teaching others
# - This code cannot be used for teaching LLMs and AI algorithms
# - This code cannot be used in commercial or proprietary products
# - This code cannot be distributed in any form
# - This code cannot be changed in any form outside of training course
# - This code cannot have its license changed
# - If you use this code in your product, you must open-source it under GPLv2
# - Exception can be granted only by the author
# %% English
# 1. Define `result: map` with lines from `DATA` converted to `dict`:
# - `datetime: datetime`
# - `level: Literal['DEBUG', 'INFO', 'WARNING', 'ERROR', 'CRITICAL']`
# - `message: str`
# 2. Run doctests - all must succeed
# %% Polish
# 1. Zdefiniuj `result: map` z liniami z `DATA` przekonwertowanymi do `dict`:
# - `datetime: datetime`
# - `level: Literal['DEBUG', 'INFO', 'WARNING', 'ERROR', 'CRITICAL']`
# - `message: str`
# 2. Uruchom doctesty - wszystkie muszą się powieść
# %% Expected
# ({'datetime': datetime.datetime(1969, 7, 14, 21, 0),
# 'level': 'INFO',
# 'message': 'Terminal countdown started'},
# {'datetime': datetime.datetime(1969, 7, 16, 13, 31, 53),
# 'level': 'WARNING',
# 'message': 'S-IC engine ignition (#5)'},
# {'datetime': datetime.datetime(1969, 7, 16, 13, 33, 23),
# 'level': 'DEBUG',
# 'message': 'Maximum dynamic pressure (735.17 lb/ft^2)'},
# ...,
# {'datetime': datetime.datetime(1969, 7, 24, 16, 50, 35),
# 'level': 'WARNING',
# 'message': 'Splashdown (went to apex-down)'},
# {'datetime': datetime.datetime(1969, 7, 24, 17, 29),
# 'level': 'INFO',
# 'message': 'Crew egress'})
# %% References
# [1] National Aeronautics and Space Administration.
# Apollo 11 timeline.
# Year: 1969. Retrieved: 2021-03-25.
# URL: https://history.nasa.gov/SP-4029/Apollo_11i_Timeline.htm
# %% Hints
# - Note, that last time has no seconds
# - This is not bug, time without seconds is in NASA history records [1]
# - `str.splitlines()`
# - `str.split(', ', maxsplit=3)`
# - `date.fromisoformat()`
# - `time.fromisoformat()`
# - `datetime.combine()`
# %% Doctests
"""
>>> import sys; sys.tracebacklimit = 0
>>> assert sys.version_info >= (3, 9), \
'Python has an is invalid version; expected: `3.9` or newer.'
>>> assert 'result' in globals(), \
'Variable `result` is not defined; assign result of your program to it.'
>>> assert result is not Ellipsis, \
'Variable `result` has an invalid value; assign result of your program to it.'
>>> assert type(result) is map, \
'Variable `result` has an invalid type; expected: `map`.'
>>> result = tuple(result)
>>> assert all(type(x) is dict for x in result), \
'Variable `result` has elements of an invalid type; all items should be: `dict`.'
>>> from pprint import pprint
>>> pprint(result, width=72, sort_dicts=False)
({'datetime': datetime.datetime(1969, 7, 14, 21, 0),
'level': 'INFO',
'message': 'Terminal countdown started'},
{'datetime': datetime.datetime(1969, 7, 16, 13, 31, 53),
'level': 'WARNING',
'message': 'S-IC engine ignition (#5)'},
{'datetime': datetime.datetime(1969, 7, 16, 13, 33, 23),
'level': 'DEBUG',
'message': 'Maximum dynamic pressure (735.17 lb/ft^2)'},
{'datetime': datetime.datetime(1969, 7, 16, 13, 34, 44),
'level': 'WARNING',
'message': 'S-II ignition'},
{'datetime': datetime.datetime(1969, 7, 16, 13, 35, 17),
'level': 'DEBUG',
'message': 'Launch escape tower jettisoned'},
{'datetime': datetime.datetime(1969, 7, 16, 13, 39, 40),
'level': 'DEBUG',
'message': 'S-II center engine cutoff'},
{'datetime': datetime.datetime(1969, 7, 16, 16, 22, 13),
'level': 'INFO',
'message': 'Translunar injection'},
{'datetime': datetime.datetime(1969, 7, 16, 16, 56, 3),
'level': 'INFO',
'message': 'CSM docked with LM/S-IVB'},
{'datetime': datetime.datetime(1969, 7, 16, 17, 21, 50),
'level': 'INFO',
'message': 'Lunar orbit insertion ignition'},
{'datetime': datetime.datetime(1969, 7, 16, 21, 43, 36),
'level': 'INFO',
'message': 'Lunar orbit circularization ignition'},
{'datetime': datetime.datetime(1969, 7, 20, 17, 44),
'level': 'INFO',
'message': 'CSM/LM undocked'},
{'datetime': datetime.datetime(1969, 7, 20, 20, 5, 5),
'level': 'WARNING',
'message': 'LM powered descent engine ignition'},
{'datetime': datetime.datetime(1969, 7, 20, 20, 10, 22),
'level': 'ERROR',
'message': 'LM 1202 alarm'},
{'datetime': datetime.datetime(1969, 7, 20, 20, 14, 18),
'level': 'ERROR',
'message': 'LM 1201 alarm'},
{'datetime': datetime.datetime(1969, 7, 20, 20, 17, 39),
'level': 'WARNING',
'message': 'LM lunar landing'},
{'datetime': datetime.datetime(1969, 7, 21, 2, 39, 33),
'level': 'DEBUG',
'message': 'EVA started (hatch open)'},
{'datetime': datetime.datetime(1969, 7, 21, 2, 56, 15),
'level': 'WARNING',
'message': '1st step taken lunar surface (CDR)'},
{'datetime': datetime.datetime(1969, 7, 21, 2, 56, 15),
'level': 'WARNING',
'message': 'Neil Armstrong first words on the Moon'},
{'datetime': datetime.datetime(1969, 7, 21, 3, 5, 58),
'level': 'DEBUG',
'message': 'Contingency sample collection started (CDR)'},
{'datetime': datetime.datetime(1969, 7, 21, 3, 15, 16),
'level': 'INFO',
'message': 'LMP on lunar surface'},
{'datetime': datetime.datetime(1969, 7, 21, 5, 11, 13),
'level': 'DEBUG',
'message': 'EVA ended (hatch closed)'},
{'datetime': datetime.datetime(1969, 7, 21, 17, 54),
'level': 'WARNING',
'message': 'LM lunar liftoff ignition (LM APS)'},
{'datetime': datetime.datetime(1969, 7, 21, 21, 35),
'level': 'INFO',
'message': 'CSM/LM docked'},
{'datetime': datetime.datetime(1969, 7, 22, 4, 55, 42),
'level': 'WARNING',
'message': 'Transearth injection ignition (SPS)'},
{'datetime': datetime.datetime(1969, 7, 24, 16, 21, 12),
'level': 'INFO',
'message': 'CM/SM separation'},
{'datetime': datetime.datetime(1969, 7, 24, 16, 35, 5),
'level': 'WARNING',
'message': 'Entry'},
{'datetime': datetime.datetime(1969, 7, 24, 16, 50, 35),
'level': 'WARNING',
'message': 'Splashdown (went to apex-down)'},
{'datetime': datetime.datetime(1969, 7, 24, 17, 29),
'level': 'INFO',
'message': 'Crew egress'})
"""
# %% Run
# - PyCharm: right-click in the editor and `Run Doctest in ...`
# - PyCharm: keyboard shortcut `Control + Shift + F10`
# - Terminal: `python -m doctest -f -v myfile.py`
# %% Imports
from datetime import date, datetime, time
# %% Types
result: map
# %% Data
DATA = """1969-07-14, 21:00:00, INFO, Terminal countdown started
1969-07-16, 13:31:53, WARNING, S-IC engine ignition (#5)
1969-07-16, 13:33:23, DEBUG, Maximum dynamic pressure (735.17 lb/ft^2)
1969-07-16, 13:34:44, WARNING, S-II ignition
1969-07-16, 13:35:17, DEBUG, Launch escape tower jettisoned
1969-07-16, 13:39:40, DEBUG, S-II center engine cutoff
1969-07-16, 16:22:13, INFO, Translunar injection
1969-07-16, 16:56:03, INFO, CSM docked with LM/S-IVB
1969-07-16, 17:21:50, INFO, Lunar orbit insertion ignition
1969-07-16, 21:43:36, INFO, Lunar orbit circularization ignition
1969-07-20, 17:44:00, INFO, CSM/LM undocked
1969-07-20, 20:05:05, WARNING, LM powered descent engine ignition
1969-07-20, 20:10:22, ERROR, LM 1202 alarm
1969-07-20, 20:14:18, ERROR, LM 1201 alarm
1969-07-20, 20:17:39, WARNING, LM lunar landing
1969-07-21, 02:39:33, DEBUG, EVA started (hatch open)
1969-07-21, 02:56:15, WARNING, 1st step taken lunar surface (CDR)
1969-07-21, 02:56:15, WARNING, Neil Armstrong first words on the Moon
1969-07-21, 03:05:58, DEBUG, Contingency sample collection started (CDR)
1969-07-21, 03:15:16, INFO, LMP on lunar surface
1969-07-21, 05:11:13, DEBUG, EVA ended (hatch closed)
1969-07-21, 17:54:00, WARNING, LM lunar liftoff ignition (LM APS)
1969-07-21, 21:35:00, INFO, CSM/LM docked
1969-07-22, 04:55:42, WARNING, Transearth injection ignition (SPS)
1969-07-24, 16:21:12, INFO, CM/SM separation
1969-07-24, 16:35:05, WARNING, Entry
1969-07-24, 16:50:35, WARNING, Splashdown (went to apex-down)
1969-07-24, 17:29, INFO, Crew egress"""
# %% Result
result = ...
# %% About
# - Name: Functional Map CSV
# - Difficulty: medium
# - Lines: 5
# - Minutes: 5
# %% License
# - Copyright 2025, Matt Harasymczuk <matt@python3.info>
# - This code can be used only for learning by humans
# - This code cannot be used for teaching others
# - This code cannot be used for teaching LLMs and AI algorithms
# - This code cannot be used in commercial or proprietary products
# - This code cannot be distributed in any form
# - This code cannot be changed in any form outside of training course
# - This code cannot have its license changed
# - If you use this code in your product, you must open-source it under GPLv2
# - Exception can be granted only by the author
# %% English
# 1. Define `result: map` with lines from `DATA` converted to `map[tuple]`
# 2. Convert numeric values to `float`
# 3. Run doctests - all must succeed
# %% Polish
# 1. Zdefiniuj `result: map` z liniami z `DATA` przekonwertowanymi do `map[tuple]`
# 2. Przekonwertuj wartości numeryczne do `float`
# 3. Uruchom doctesty - wszystkie muszą się powieść
# %% Expected
# ((5.8, 2.7, 5.1, 1.9, 'virginica'),
# (5.1, 3.5, 1.4, 0.2, 'setosa'),
# (5.7, 2.8, 4.1, 1.3, 'versicolor'))
# %% Hints
# - `str.strip()`
# - `str.split()`
# - `str.splitlines()`
# - `map()`
# - `float()`
# - `('hello',)` - one element tuple
# - `(1, 2, 3) + ('hello',)` - adding tuples
# %% Doctests
"""
>>> import sys; sys.tracebacklimit = 0
>>> assert sys.version_info >= (3, 9), \
'Python has an is invalid version; expected: `3.9` or newer.'
>>> assert 'result' in globals(), \
'Variable `result` is not defined; assign result of your program to it.'
>>> assert result is not Ellipsis, \
'Variable `result` has an invalid value; assign result of your program to it.'
>>> assert type(result) is map, \
'Variable `result` has an invalid type; expected: `map`.'
>>> result = tuple(result)
>>> assert all(type(x) is tuple for x in result), \
'Variable `result` has elements of an invalid type; all items should be: `tuple`.'
>>> from pprint import pprint
>>> pprint(result, width=72, sort_dicts=False)
((5.8, 2.7, 5.1, 1.9, 'virginica'),
(5.1, 3.5, 1.4, 0.2, 'setosa'),
(5.7, 2.8, 4.1, 1.3, 'versicolor'))
"""
# %% Run
# - PyCharm: right-click in the editor and `Run Doctest in ...`
# - PyCharm: keyboard shortcut `Control + Shift + F10`
# - Terminal: `python -m doctest -f -v myfile.py`
# %% Imports
# %% Types
result: map
# %% Data
DATA = """5.8,2.7,5.1,1.9,virginica
5.1,3.5,1.4,0.2,setosa
5.7,2.8,4.1,1.3,versicolor"""
# %% Result
result = ...
# %% About
# - Name: Functional Map ReadTypeCast
# - Difficulty: medium
# - Lines: 6
# - Minutes: 8
# %% License
# - Copyright 2025, Matt Harasymczuk <matt@python3.info>
# - This code can be used only for learning by humans
# - This code cannot be used for teaching others
# - This code cannot be used for teaching LLMs and AI algorithms
# - This code cannot be used in commercial or proprietary products
# - This code cannot be distributed in any form
# - This code cannot be changed in any form outside of training course
# - This code cannot have its license changed
# - If you use this code in your product, you must open-source it under GPLv2
# - Exception can be granted only by the author
# %% English
# 1. Define `result: map` with lines from `DATA` converted to `map[tuple]`
# 2. Convert numeric values to `float`
# 3. Replace species number with species name from `label_encoder`
# 4. Run doctests - all must succeed
# %% Polish
# 1. Zdefiniuj `result: map` z liniami z `DATA` przekonwertowanymi do `map[tuple]`
# 2. Przekonwertuj wartości numeryczne do `float`
# 3. Zamień numer gatunku na nazwę gatunku z `label_encoder`
# 4. Uruchom doctesty - wszystkie muszą się powieść
# %% Expected
# ((5.8, 2.7, 5.1, 1.9, 'virginica'),
# (5.1, 3.5, 1.4, 0.2, 'setosa'),
# (5.7, 2.8, 4.1, 1.3, 'versicolor'))
# %% Hints
# - `str.splitlines()`
# - `str.strip()`
# - `str.split()`
# - `result, *others = 1, 2, 3, 4`
# - `dict()`
# - `enumerate()`
# - `map()`
# - `float()`
# - `('hello',)` - one element tuple
# - `(1, 2, 3) + ('hello',)` - adding tuples
# %% Doctests
"""
>>> import sys; sys.tracebacklimit = 0
>>> assert sys.version_info >= (3, 9), \
'Python has an is invalid version; expected: `3.9` or newer.'
>>> assert 'result' in globals(), \
'Variable `result` is not defined; assign result of your program to it.'
>>> assert result is not Ellipsis, \
'Variable `result` has an invalid value; assign result of your program to it.'
>>> assert type(result) is map, \
'Variable `result` has an invalid type; expected: `map`.'
>>> result = tuple(result)
>>> assert all(type(x) is tuple for x in result), \
'Variable `result` has elements of an invalid type; all items should be: `tuple`.'
>>> from pprint import pprint
>>> pprint(result, width=72, sort_dicts=False)
((5.8, 2.7, 5.1, 1.9, 'virginica'),
(5.1, 3.5, 1.4, 0.2, 'setosa'),
(5.7, 2.8, 4.1, 1.3, 'versicolor'))
"""
# %% Run
# - PyCharm: right-click in the editor and `Run Doctest in ...`
# - PyCharm: keyboard shortcut `Control + Shift + F10`
# - Terminal: `python -m doctest -f -v myfile.py`
# %% Imports
# %% Types
result: map
# %% Data
DATA = """3,4,setosa,virginica,versicolor
5.8,2.7,5.1,1.9,1
5.1,3.5,1.4,0.2,0
5.7,2.8,4.1,1.3,2"""
header, *lines = DATA.splitlines()
nrows, nfeatures, *class_labels = header.strip().split(',')
label_encoder = dict(enumerate(class_labels))
# %% Result
result = ...
# %% About
# - Name: Functional Map Hosts
# - Difficulty: medium
# - Lines: 4
# - Minutes: 5
# %% License
# - Copyright 2025, Matt Harasymczuk <matt@python3.info>
# - This code can be used only for learning by humans
# - This code cannot be used for teaching others
# - This code cannot be used for teaching LLMs and AI algorithms
# - This code cannot be used in commercial or proprietary products
# - This code cannot be distributed in any form
# - This code cannot be changed in any form outside of training course
# - This code cannot have its license changed
# - If you use this code in your product, you must open-source it under GPLv2
# - Exception can be granted only by the author
# %% English
# 1. Define `result: map` with lines from `DATA` converted to `dict`:
# - `ip: str`
# - `hosts: list[str]`
# 2. Run doctests - all must succeed
# %% Polish
# 1. Zdefiniuj `result: map` z liniami z `DATA` przekonwertowanymi do `dict`:
# - `ip: str`
# - `hosts: list[str]`
# 2. Uruchom doctesty - wszystkie muszą się powieść
# %% Expected
# ({'ip': '127.0.0.1', 'hosts': ['localhost']},
# {'ip': '127.0.0.1', 'hosts': ['mycomputer']},
# {'ip': '172.16.0.1', 'hosts': ['example.com']},
# {'ip': '192.168.0.1', 'hosts': ['example.edu', 'example.org']},
# {'ip': '10.0.0.1', 'hosts': ['example.net']},
# {'ip': '255.255.255.255', 'hosts': ['broadcasthost']},
# {'ip': '::1', 'hosts': ['localhost']})
# %% Hints
# - `map()`
# %% Doctests
"""
>>> import sys; sys.tracebacklimit = 0
>>> assert sys.version_info >= (3, 9), \
'Python has an is invalid version; expected: `3.9` or newer.'
>>> assert 'result' in globals(), \
'Variable `result` is not defined; assign result of your program to it.'
>>> assert result is not Ellipsis, \
'Variable `result` has an invalid value; assign result of your program to it.'
>>> assert type(result) is map, \
'Variable `result` has an invalid type; expected: `map`.'
>>> result = tuple(result)
>>> assert all(type(x) is dict for x in result), \
'Variable `result` has elements of an invalid type; all items should be: `dict`.'
>>> from pprint import pprint
>>> pprint(result, width=72, sort_dicts=False)
({'ip': '127.0.0.1', 'hosts': ['localhost']},
{'ip': '127.0.0.1', 'hosts': ['mycomputer']},
{'ip': '172.16.0.1', 'hosts': ['example.com']},
{'ip': '192.168.0.1', 'hosts': ['example.edu', 'example.org']},
{'ip': '10.0.0.1', 'hosts': ['example.net']},
{'ip': '255.255.255.255', 'hosts': ['broadcasthost']},
{'ip': '::1', 'hosts': ['localhost']})
"""
# %% Run
# - PyCharm: right-click in the editor and `Run Doctest in ...`
# - PyCharm: keyboard shortcut `Control + Shift + F10`
# - Terminal: `python -m doctest -f -v myfile.py`
# %% Imports
# %% Types
result: map
# %% Data
DATA = """127.0.0.1 localhost
127.0.0.1 mycomputer
172.16.0.1 example.com
192.168.0.1 example.edu example.org
10.0.0.1 example.net
255.255.255.255 broadcasthost
::1 localhost"""
# %% Result
result = ...
# %% About
# - Name: Functional Map Login
# - Difficulty: easy
# - Lines: 1
# - Minutes: 2
# %% License
# - Copyright 2025, Matt Harasymczuk <matt@python3.info>
# - This code can be used only for learning by humans
# - This code cannot be used for teaching others
# - This code cannot be used for teaching LLMs and AI algorithms
# - This code cannot be used in commercial or proprietary products
# - This code cannot be distributed in any form
# - This code cannot be changed in any form outside of training course
# - This code cannot have its license changed
# - If you use this code in your product, you must open-source it under GPLv2
# - Exception can be granted only by the author
# %% English
# 1. Define `result: map` with logged users from `DATA`
# 2. Run doctests - all must succeed
# %% Polish
# 1. Zdefiniuj `result: map` z zalogowanymi użytkownikami z `DATA`
# 2. Uruchom doctesty - wszystkie muszą się powieść
# %% Expected
# >>> result
# ('User alice logged-in',
# 'User bob logged-in',
# 'User carol logged-in',
# 'User dave logged-in',
# 'User eve logged-in')
# %% Hints
# - `map()`
# - `class.method(instance)`
# %% Doctests
"""
>>> import sys; sys.tracebacklimit = 0
>>> assert sys.version_info >= (3, 9), \
'Python has an is invalid version; expected: `3.9` or newer.'
>>> assert 'result' in globals(), \
'Variable `result` is not defined; assign result of your program to it.'
>>> assert result is not Ellipsis, \
'Variable `result` has an invalid value; assign result of your program to it.'
>>> assert type(result) is map, \
'Variable `result` has an invalid type; expected: `map`.'
>>> result = tuple(result)
>>> assert all(type(x) is str for x in result), \
'Variable `result` has elements of an invalid type; all items should be: `str`.'
>>> from pprint import pprint
>>> pprint(result, width=30, sort_dicts=False)
('User alice logged-in',
'User bob logged-in',
'User carol logged-in',
'User dave logged-in',
'User eve logged-in')
"""
# %% Run
# - PyCharm: right-click in the editor and `Run Doctest in ...`
# - PyCharm: keyboard shortcut `Control + Shift + F10`
# - Terminal: `python -m doctest -f -v myfile.py`
# %% Imports
# %% Types
result: map
# %% Data
class User:
def __init__(self, username, uid):
self.username = username
self.uid = uid
def login(self):
return f'User {self.username} logged-in'
USERS = [
User('alice', uid=1000),
User('bob', uid=1001),
User('carol', uid=1002),
User('dave', uid=1003),
User('eve', uid=1004),
]
# %% Result
result = ...
# %% About
# - Name: Functional Map JSON
# - Difficulty: medium
# - Lines: 6
# - Minutes: 8
# %% License
# - Copyright 2025, Matt Harasymczuk <matt@python3.info>
# - This code can be used only for learning by humans
# - This code cannot be used for teaching others
# - This code cannot be used for teaching LLMs and AI algorithms
# - This code cannot be used in commercial or proprietary products
# - This code cannot be distributed in any form
# - This code cannot be changed in any form outside of training course
# - This code cannot have its license changed
# - If you use this code in your product, you must open-source it under GPLv2
# - Exception can be granted only by the author
# %% English
# 1. Convert from JSON format to Python
# 2. Create instances of `Setosa`, `Virginica`, `Versicolor`
# classes based on value in field "species"
# 3. Generate instances in `result: map`
# 4. Run doctests - all must succeed
# %% Polish
# 1. Przekonwertuj dane z JSON do Python
# 2. Twórz obiekty klas `Setosa`, `Virginica`, `Versicolor`
# w zależności od wartości pola "species"
# 3. Generuj instancje w `result: map`
# 4. Uruchom doctesty - wszystkie muszą się powieść
# %% Expected
# >>> result[0]
# Virginica(sepal_length=5.8, sepal_width=2.7, petal_length=5.1, petal_width=1.9)
#
# >>> result[1]
# Setosa(sepal_length=5.1, sepal_width=3.5, petal_length=1.4, petal_width=0.2)
# %% Hints
# - `dict.pop()`
# - `globals()[clsname]`
# - `cls(*dict)`
# - `json.loads()`
# %% Doctests
"""
>>> import sys; sys.tracebacklimit = 0
>>> assert sys.version_info >= (3, 9), \
'Python has an is invalid version; expected: `3.9` or newer.'
>>> assert type(result) is map
>>> result = list(result)
>>> assert len(result) == 9
>>> classes = (Setosa, Virginica, Versicolor)
>>> assert all(type(row) in classes for row in result)
>>> result[0]
Virginica(sepal_length=5.8, sepal_width=2.7, petal_length=5.1, petal_width=1.9)
>>> result[1]
Setosa(sepal_length=5.1, sepal_width=3.5, petal_length=1.4, petal_width=0.2)
"""
# %% Run
# - PyCharm: right-click in the editor and `Run Doctest in ...`
# - PyCharm: keyboard shortcut `Control + Shift + F10`
# - Terminal: `python -m doctest -f -v myfile.py`
# %% Imports
import json
from dataclasses import dataclass
# %% Types
result: map
# %% Data
DATA = (
'[{"sepal_length":5.8,"sepal_width":2.7,"petal_length":5.1,"petal_widt'
'h":1.9,"species":"virginica"},{"sepal_length":5.1,"sepal_width":3.5,"'
'petal_length":1.4,"petal_width":0.2,"species":"setosa"},{"sepal_lengt'
'h":5.7,"sepal_width":2.8,"petal_length":4.1,"petal_width":1.3,"specie'
's":"versicolor"},{"sepal_length":6.3,"sepal_width":2.9,"petal_length"'
':5.6,"petal_width":1.8,"species":"virginica"},{"sepal_length":6.4,"se'
'pal_width":3.2,"petal_length":4.5,"petal_width":1.5,"species":"versic'
'olor"},{"sepal_length":4.7,"sepal_width":3.2,"petal_length":1.3,"peta'
'l_width":0.2,"species":"setosa"},{"sepal_length":7.0,"sepal_width":3.'
'2,"petal_length":4.7,"petal_width":1.4,"species":"versicolor"},{"sepa'
'l_length":7.6,"sepal_width":3.0,"petal_length":6.6,"petal_width":2.1,'
'"species":"virginica"},{"sepal_length":4.9,"sepal_width":3.0,"petal_l'
'ength":1.4,"petal_width":0.2,"species":"setosa"}]'
)
@dataclass
class Iris:
sepal_length: float
sepal_width: float
petal_length: float
petal_width: float
class Setosa(Iris):
pass
class Virginica(Iris):
pass
class Versicolor(Iris):
pass
# %% Result
result = ...