15.1. CSV About
CSV - Comma/Character Separated Values
No CSV formal standard, just a practice
Flat file (2D) without relations
Relations has to be flatten (serialization, additional columns, etc...)
Typically first line (header) represents column names
Rarely first line can also have a structure (nrows, ncols)
Internationalization: encoding
Localization: decimal separator, thousands separator, date format
Parameters: delimiter, quotechar, quoting, lineterminator, dialect
Example CSV file:
firstname,lastname,age
Alice,Apricot,30
Bob,Blackthorn,31
Carol,Corn,32
Dave,Durian,33
Eve,Elderberry,34
Mallory,Melon,15
15.1.1. First Line
Typically first line (header) represents column names
First line can also have a structure
Used in Machine Learning
nrows- number of rowsncols- number of columnsnvalues- number of values
File without header:
Alice,Apricot,30
Bob,Blackthorn,31
Carol,Corn,32
Dave,Durian,33
Eve,Elderberry,34
Mallory,Melon,15
First line is a header:
firstname,lastname,age
Alice,Apricot,30
Bob,Blackthorn,31
Carol,Corn,32
Dave,Durian,33
Eve,Elderberry,34
Mallory,Melon,15
First line is a structure (number of rows nrows and columns ncols):
6,3
Alice,Apricot,users
Bob,Blackthorn,users
Carol,Corn,staff
Dave,Durian,staff
Eve,Elderberry,admins
Mallory,Melon,admins
First line is a structure: (number of rows nrows and features nfeatures,
followed by class_labels values for label column:
6,2,users,staff,admins
Alice,Apricot,1
Bob,Blackthorn,1
Carol,Corn,2
Dave,Durian,2
Eve,Elderberry,3
Mallory,Melon,3
Later, class_labels can be decoded using label_encoder dictionary:
>>> label_encoder = {
... 1: 'users',
... 2: 'staff',
... 3: 'admins',
... }
15.1.2. Relations
Flat file (2D) without relations
Relations has to be flatten (serialization, additional columns, etc...)
firstname,lastname,age
Alice,Apricot,30
Bob,Blackthorn,31
Carol,Corn,32
Dave,Durian,33
Eve,Elderberry,34
Mallory,Melon,15
firstname,lastname,age,groups
Alice,Apricot,30,users;staff
Bob,Blackthorn,31,users;staff
Carol,Corn,32,users
Dave,Durian,33,users
Eve,Elderberry,34,users;staff;admins
Mallory,Melon,15,
firstname,lastname,age,group_1,group_2,group_3
Alice,Apricot,30,users,staff
Bob,Blackthorn,31,users,staff
Carol,Corn,32,users
Dave,Durian,33,users
Eve,Elderberry,34,users,staff,admins
Mallory,Melon,15,
15.1.3. Delimiter
csvmodule expects delimiter to be 1-character in length
delimiter=',':
firstname,lastname,age
Alice,Apricot,30
Bob,Blackthorn,31
Carol,Corn,32
Dave,Durian,33
Eve,Elderberry,34
Mallory,Melon,15
delimiter=';':
firstname;lastname;age
Alice;Apricot;30
Bob;Blackthorn;31
Carol;Corn;32
Dave;Durian;33
Eve;Elderberry;34
Mallory;Melon;15
delimiter=':':
firstname:lastname:age
Alice:Apricot:30
Bob:Blackthorn:31
Carol:Corn:32
Dave:Durian:33
Eve:Elderberry:34
Mallory:Melon:15
delimiter='|':
firstname|lastname|age
Alice|Apricot|30
Bob|Blackthorn|31
Carol|Corn|32
Dave|Durian|33
Eve|Elderberry|34
Mallory|Melon|15
delimiter='|':
| Firstname | Lastname | Age |
|-----------|------------|-----|
| Alice | Apricot | 30 |
| Bob | Blackthorn | 31 |
| Carol | Corn | 32 |
| Dave | Durian | 33 |
| Eve | Elderberry | 34 |
| Mallory | Melon | 15 |
delimiter='\t':
firstname lastname age
Alice Apricot 30
Bob Blackthorn 31
Carol Corn 32
Dave Durian 33
Eve Elderberry 34
Mallory Melon 15
15.1.4. Quotechar
"- quote char (best)'- apostrophe
quotechar='"':
"firstname","lastname","age"
"Alice","Apricot","30"
"Bob","Blackthorn","31"
"Carol","Corn","32"
"Dave","Durian","33"
"Eve","Elderberry","34"
"Mallory","Melon","15"
quotechar="'":
'firstname','lastname','age'
'Alice','Apricot','30'
'Bob','Blackthorn','31'
'Carol','Corn','32'
'Dave','Durian','33'
'Eve','Elderberry','34'
'Mallory','Melon','15'
quotechar='|':
|firstname|,|lastname|,|age|
|Alice|,|Apricot|,|30|
|Bob|,|Blackthorn|,|31|
|Carol|,|Corn|,|32|
|Dave|,|Durian|,|33|
|Eve|,|Elderberry|,|34|
|Mallory|,|Melon|,|15|
quotechar='/':
/firstname/,/lastname/,/age/
/Alice/,/Apricot/,/30/
/Bob/,/Blackthorn/,/31/
/Carol/,/Corn/,/32/
/Dave/,/Durian/,/33/
/Eve/,/Elderberry/,/34/
/Mallory/,/Melon/,/15/
/He said: "It's Monty Python"/
15.1.5. Quoting
csv.QUOTE_ALL(safest)csv.QUOTE_MINIMALcsv.QUOTE_NONEcsv.QUOTE_NONNUMERIC
quoting=csv.QUOTE_ALL:
"firstname","lastname","age"
"Alice","Apricot","30"
"Bob","Blackthorn","31"
"Carol","Corn","32"
"Dave","Durian","33"
"Eve","Elderberry","34"
"Mallory","Melon","15"
quoting=csv.QUOTE_MINIMAL:
firstname,lastname,age
Alice,Apricot,30
Bob,Blackthorn,31
Carol,Corn,32
Dave,Durian,33
Eve,Elderberry,34
Mallory,Melon,15
quoting=csv.QUOTE_NONE:
firstname,lastname,age
Alice,Apricot,30
Bob,Blackthorn,31
Carol,Corn,32
Dave,Durian,33
Eve,Elderberry,34
Mallory,Melon,15
quoting=csv.QUOTE_NONNUMERIC:
"firstname","lastname","age"
"Alice","Apricot",30
"Bob","Blackthorn",31
"Carol","Corn",32
"Dave","Durian",33
"Eve","Elderberry",34
"Mallory","Melon",15
15.1.6. Lineterminator
\r\n- New line on Windows\n- New line on*nix*nixoperating systems: Linux, macOS, BSD and other POSIX compliant OSes (excluding Windows)
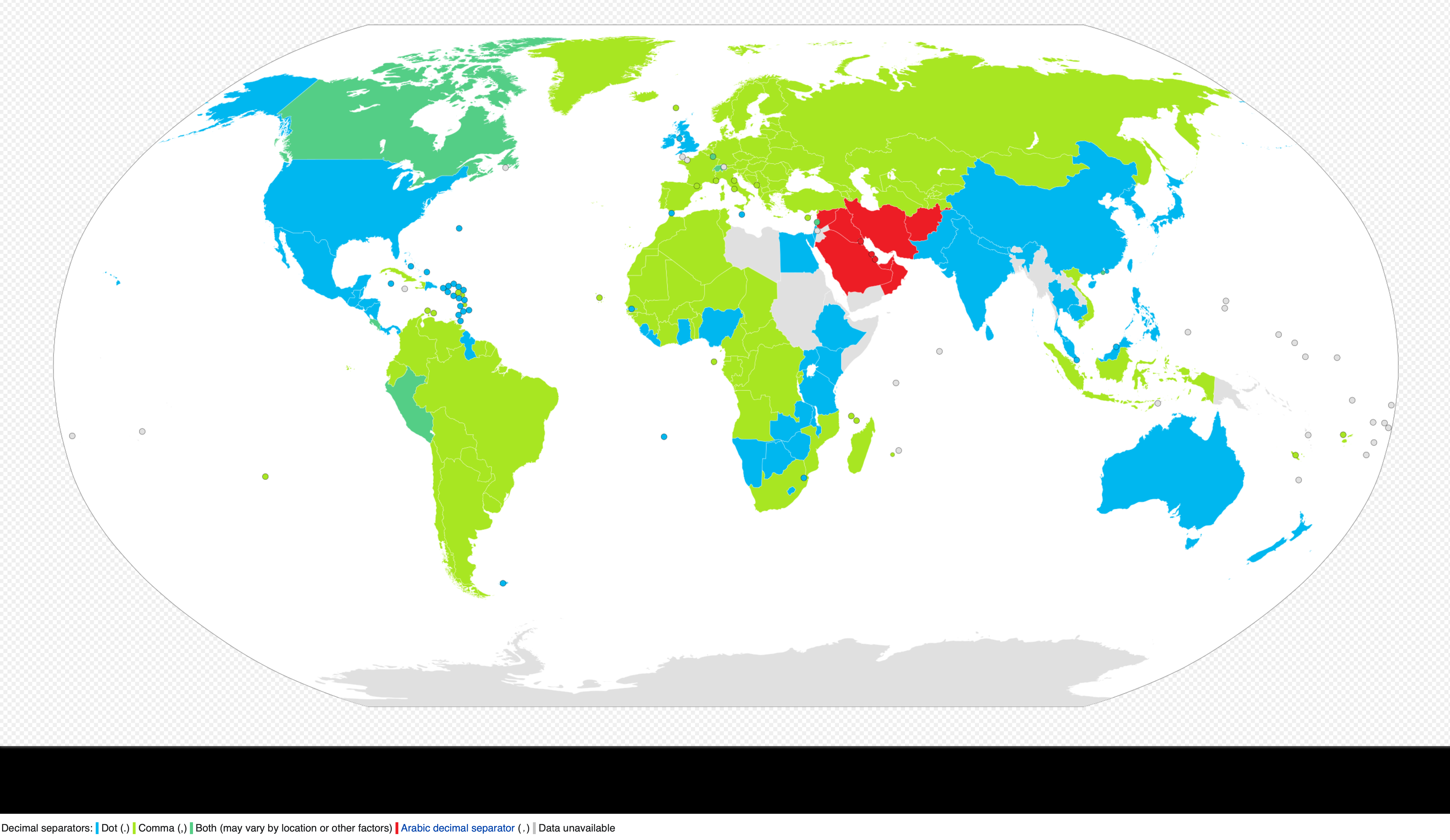
15.1.7. Decimal Separator
1.0- Decimal point1,0- Decimal comma0٫1- Arabic decimal separator (Left to right)More information: [1]
firstname,lastname,age
Alice,Apricot,30.0
Bob,Blackthorn,31.0
Carol,Corn,32.0
Dave,Durian,33.0
Eve,Elderberry,34.0
Mallory,Melon,15.0
firstname;lastname;age
Alice;Apricot;30,0
Bob;Blackthorn;31,0
Carol;Corn;32,0
Dave;Durian;33,0
Eve;Elderberry;34,0
Mallory;Melon;15,0
15.1.8. Thousands Separator
1000000- None1'000'000- Apostrophe1 000 000- Space, the internationally recommended thousands separator1.000.000- Period, used in many non-English speaking countries1,000,000- Comma, used in most English-speaking countries1_000_000- Python separator for better readability
15.1.9. Thousands Grouping
1,000,000,000- Groups of three1,00,00,00,000- Groups of three and two (India)
15.1.10. Date and Time
>>> date = '2000-01-02'
>>> date = '02-01-2000'
>>>
>>> date = '2.1.2000'
>>> date = '1.2.2000'
>>>
>>> date = '02.01.2000'
>>> date = '01.02.2000'
>>>
>>> date = '01/02/2000'
>>> date = '1/2/00'
>>>
>>> date = 'Jan 2, 2000'
>>> date = 'Jan 2nd, 2000'
>>> time = '12:00'
>>> time = '12:00:00'
>>> time = '12:00:00.0000000'
>>>
>>> time = '12:00 pm'
>>> time = '12:00 am'
>>> duration = '01:20:00'
>>> duration = '1h 20m'
>>> duration = '1 hours 20 minutes'
15.1.11. Encoding
utf-8- international standard (should be always used!)iso-8859-1- ISO standard for Western Europe and USAiso-8859-2- ISO standard for Central Europe (including Poland)cp1250orwindows-1250- Central European encoding on Windowscp1251orwindows-1251- Eastern European encoding on Windowscp1252orwindows-1252- Western European encoding on WindowsASCII- ASCII characters only
with open(FILE, encoding='utf-8') as file:
...
15.1.12. Dialects
import csv
csv.list_dialects()
# ['excel', 'excel-tab', 'unix']
Microsoft Excel 2016-2020:
quoting=csv.QUOTE_MINIMALquotechar='"'delimiter=','ordelimiter=';'depending on Windows locale decimal separatorlineterminator='\r\n'encoding='...'- depends on Windows locale typicallywindows-*
Microsoft Excel macOS:
quoting=csv.QUOTE_MINIMALquotechar='"'delimiter=','lineterminator='\r\n'encoding='utf-8'
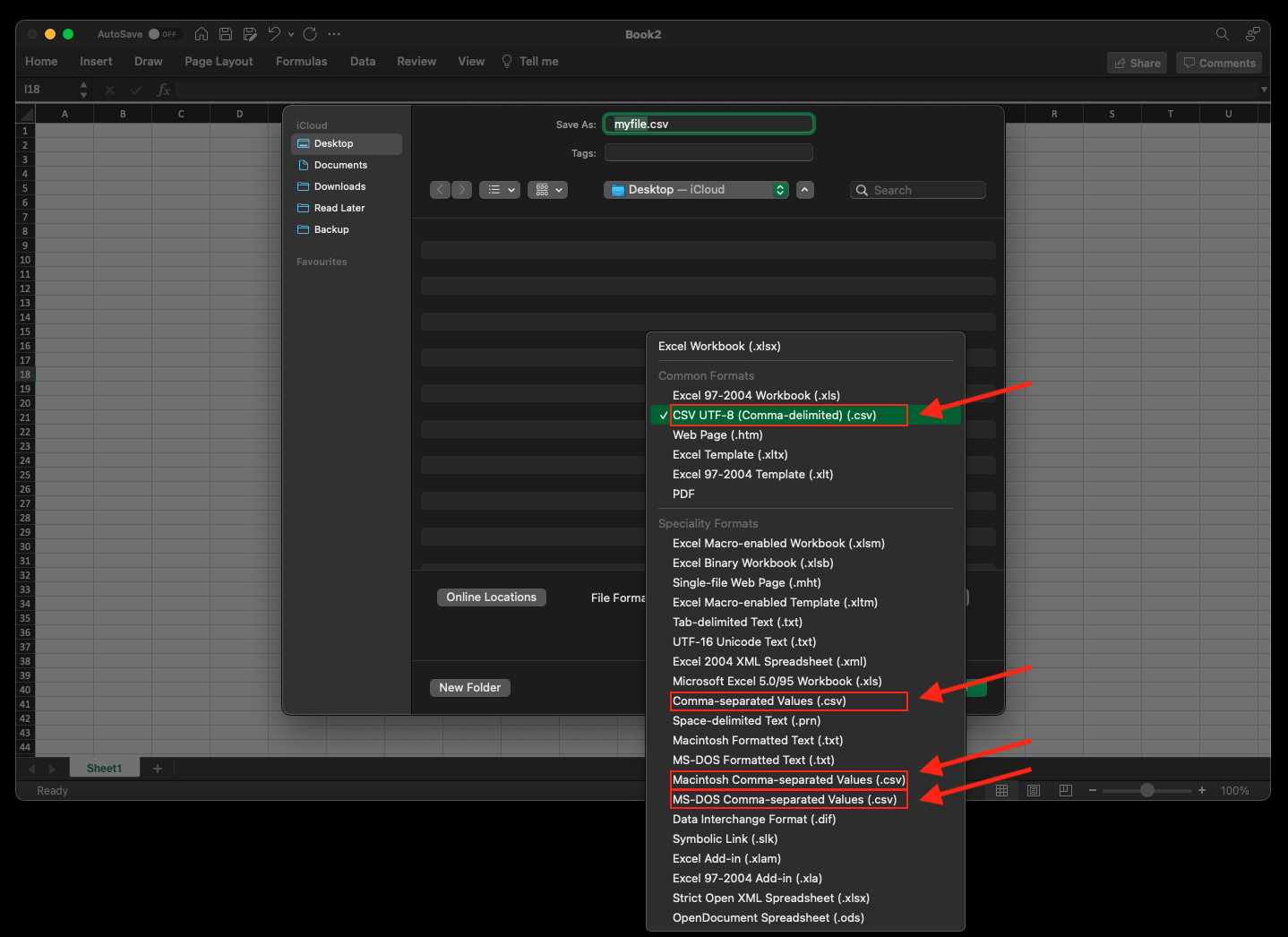
Microsoft export options:
$ file utf8.csv
utf8.csv: CSV text
$ cat utf8.csv
Firstname,Lastname,Age,Comment
Alice,Apricot,21,zażółć gęślą jaźń
Bob,Blackthorn,21.5,"Some, comment"
,,"21,5",Some; Comment
$ file standard.csv
standard.csv: CSV text
$ cat standard.csv
Firstname,Lastname,Age,Comment
Alice,Apricot,21,za_?__ g__l_ ja__
Bob,Blackthorn,21.5,"Some, comment"
,,"21,5",Some; Comment
$ file dos.csv
dos.csv: CSV text
$ cat dos.csv
Firstname,Lastname,Age,Comment
Alice,Apricot,21,za_?__ g__l_ ja__
Bob,Blackthorn,21.5,"Some, comment"
,,"21,5",Some; Comment
$ file macintosh.csv
macintosh.csv: Non-ISO extended-ASCII text, with CR line terminators
$ cat macintosh.csv
,,"21,5",Some; Comment
15.1.13. Good Practices
Always specify:
delimiter=','tocsv.DictReader()object
quotechar='"'tocsv.DictReader()object
quoting=csv.QUOTE_ALLtocsv.DictReader()object
lineterminator='\n'tocsv.DictReader()object
encoding='utf-8'toopen()function (especially when working with Microsoft Excel)