11.1. Loop For About¶
>>> data = ['a', 'b', 'c']
>>> i = 0
>>>
>>> while i < len(data):
... x = data[i]
... print(x)
... i += 1
a
b
c
>>> data = ['a', 'b', 'c']
>>>
>>> for x in data:
... print(x)
a
b
c
11.1.1. Syntax¶
ITERABLEmust implementiteratorinterfaceMore information in Protocol Iterator
For loop syntax:
for <variable> in <iterable>:
<do something>
>>> for digit in [1, 2, 3]:
... pass
11.1.2. Iterating Sequences¶
Iterating works for builtin sequences:
strbyteslisttuplesetdict
>>> DATA = 'NASA'
>>>
>>> for letter in DATA:
... print(letter)
N
A
S
A
>>> DATA = [1, 2, 3]
>>>
>>> for digit in DATA:
... print(digit)
1
2
3
>>> DATA = ['a', 'b', 'c']
>>>
>>> for letter in DATA:
... print(letter)
a
b
c
>>> users = [
... 'Mark Watney',
... 'Melissa Lewis',
... 'Rick Martinez',
... ]
>>>
>>> for user in users:
... print(user)
Mark Watney
Melissa Lewis
Rick Martinez
>>> DATA = [5.1, 3.5, 1.4, 0.2, 'setosa']
>>>
>>> for value in DATA:
... print(value)
5.1
3.5
1.4
0.2
setosa
>>> for current in [1,2,3]:
... print(current)
1
2
3
11.1.3. Note to the Programmers of Other Languages¶
There are several types of loops in general:
for
foreach
while
do while
until
But in Python we have only two:
while
for
This does not takes into consideration comprehensions and generator expressions, which will be covered in next chapters.
Note, that Python for is not the same as for in other languages,
such as C, C++, C#, JAVA, Java Script. Python for loop is more like
foreach. Check the following example in JAVA:
char[] DATA = {'a', 'b', 'c'};
forEach (var letter : DATA) {
System.out.println(letter);
}
$data = array('a', 'b', 'c');
foreach ($data as $letter) {
echo $letter;
}
DATA = ['a', 'b', 'c']
for (let letter of DATA) {
console.log(letter)
}
And this relates to Python regular for loop:
>>> DATA = ['a', 'b', 'c']
>>>
>>> for letter in DATA:
... print(letter)
a
b
c
Regular for loop in other languages looks like that (example in C++):
char DATA[] = {'a', 'b', 'c'}
for (int i = 0; i < std::size(DATA); i++) {
letter = data[i];
printf(letter);
}
Python equivalent will be:
>>> DATA = ['a', 'b', 'c']
>>> i = 0
>>>
>>> while i < len(DATA):
... letter = DATA[i]
... print(letter)
... i += 1
a
b
c
Yes, that's true, it is a while loop. This is due to the fact, that for
loop from other languages is more like a while loop in Python.
Nevertheless, the very common bad practice is to do range(len()):
>>> data = ['a', 'b', 'c']
>>>
>>> for i in range(len(data)):
... letter = data[i]
... print(letter)
a
b
c
Note, how similar are those concepts. This is trying to take syntax from other
languages and apply it to Python. range(len()) is considered a bad practice
and it will not work with generators. But it gives similar look-and-feel.
Please remember:
Python
foris more likeforeachin other languages.Python
whileis more likeforin other languages.
11.1.4. Good Practices¶
The longer the loop scope, the longer the variable name should be
Avoid one letters if scope is longer than one line
Prefer locally meaningful name over generic names
Generic names:
obj- generic name (in Python everything is an object)element- generic nameitem- generic namex- ok for oneliners, bad for more than one linee- ok for oneliners, bad for more than one linel- bado- badd- bad (for digit)
Locally meaningful name:
letterfeaturedigitpersoncolorusernameetc.
Special meaning (by convention):
i- for loop counter_- if value is not used
>>> for x in [1, 2, 3]:
... print(x)
1
2
3
>>> for i in range(0,3):
... print(i)
0
1
2
11.1.5. Use Case - 0x01¶
>>> def spawn_thread():
... ...
>>>
>>>
>>> for _ in range(3):
... spawn_thread()
11.1.6. Use Case - 0x02¶
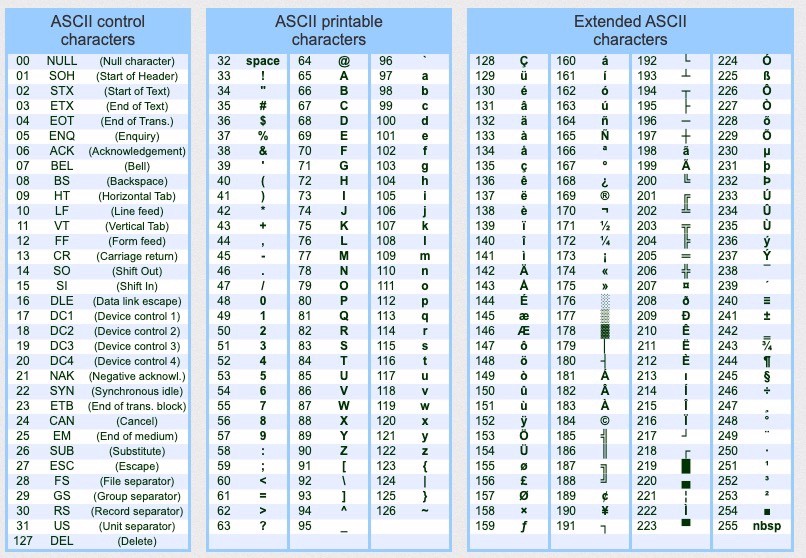{kind=link}
>>> text = 'hello'
>>> text.upper()
'HELLO'
>>> i = 0
>>> result = ''
>>> offset = 32 # ASCII table between lowercase and uppercase letters
>>>
>>> while i < len(text):
... letter = ord(text[i])
... letter = chr(letter-32)
... result += letter
... i += 1
...
>>> result
'HELLO'
>>>
... if value == 97:
... return 'a'
... elif value == 99:
... return 'b'
11.1.7. Assignments¶
"""
* Assignment: Loop For Count
* Type: class assignment
* Complexity: easy
* Lines of code: 7 lines
* Time: 5 min
English:
1. Count occurrences of each color
2. Do not use `list.count()`
3. Run doctests - all must succeed
Polish:
1. Zlicz wystąpienia każdego z kolorów
2. Nie używaj `list.count()`
3. Uruchom doctesty - wszystkie muszą się powieść
Tests:
>>> import sys; sys.tracebacklimit = 0
>>> assert red is not Ellipsis, \
'Assign your result to variable `red`'
>>> assert green is not Ellipsis, \
'Assign your result to variable `green`'
>>> assert blue is not Ellipsis, \
'Assign your result to variable `blue`'
>>> assert type(red) is int, \
'Variable `red` has invalid type, should be list'
>>> assert type(green) is int, \
'Variable `green` has invalid type, should be list'
>>> assert type(blue) is int, \
'Variable `blue` has invalid type, should be list'
>>> red
3
>>> green
2
>>> blue
2
"""
DATA = ['red', 'green', 'blue', 'red', 'green', 'red', 'blue']
# Number of 'red' elements in DATA
# type: int
red = ...
# Number of 'green' elements in DATA
# type: int
green = ...
# Number of 'blue' elements in DATA
# type: int
blue = ...
"""
* Assignment: Loop For Range
* Type: class assignment
* Complexity: easy
* Lines of code: 3 lines
* Time: 3 min
English:
1. Generate `result: list[int]` with numbers from 0 (inclusive) to 5 (exclusive)
2. You can use `range()` in a loop, but not conversion: `list(range())`
3. Run doctests - all must succeed
Polish:
1. Wygeneruj `result: list[int]` z liczbami od 0 (włącznie) do 5 (rozłącznie)
2. Możesz użyć `range()` w pętli, ale nie konwersji: `list(range())`
3. Uruchom doctesty - wszystkie muszą się powieść
Tests:
>>> import sys; sys.tracebacklimit = 0
>>> assert result is not Ellipsis, \
'Assign your result to variable `result`'
>>> assert type(result) is list, \
'Variable `result` has invalid type, should be list'
>>> assert all(type(x) is int for x in result), \
'All elements in `result` should be int'
>>> result
[0, 1, 2, 3, 4]
"""
# List with numbers from 0 to 5 (exclusive)
# type: list[int]
result = ...
"""
* Assignment: Loop For Counter
* Type: class assignment
* Complexity: easy
* Lines of code: 5 lines
* Time: 5 min
English:
1. Iterate over `DATA`
2. Count occurrences of each number
3. Create empty `result: dict[int, int]`:
a. key - digit
b. value - number of occurrences
4. Iterating over numbers check if number is already in `result`:
a. If first occurrence, then add it to `result` with value 1
b. If exists, then increment the value by 1
5. Run doctests - all must succeed
Polish:
1. Iteruj po `DATA`
2. Policz wystąpienia każdej z cyfr
3. Stwórz pusty `result: dict[int, int]`:
a. klucz - cyfra
b. wartość - liczba wystąpień
4. Iterując po cyfrach sprawdź czy cyfra znajduje się już w `result`:
a. Jeżeli pierwsze wystąpienie, to dodaj ją do `result` z wartością 1
b. Jeżeli istnieje, to zwiększ w wartość o 1
5. Uruchom doctesty - wszystkie muszą się powieść
Tests:
>>> import sys; sys.tracebacklimit = 0
>>> assert result is not Ellipsis, \
'Assign your result to variable `result`'
>>> assert type(result) is dict, \
'Variable `result` has invalid type, should be dict'
>>> assert all(type(x) is int for x in result.keys())
>>> assert all(type(x) is int for x in result.values())
>>> assert all(x in result.keys() for x in range(0, 10))
>>> result
{1: 7, 4: 8, 6: 4, 7: 4, 5: 4, 0: 7, 9: 5, 8: 6, 2: 2, 3: 3}
"""
DATA = [
1, 4, 6, 7, 4, 4, 4, 5, 1, 7, 0,
0, 6, 5, 0, 0, 9, 7, 0, 4, 4, 8,
2, 4, 0, 0, 1, 9, 1, 7, 8, 8, 9,
1, 3, 5, 6, 8, 2, 8, 1, 3, 9, 5,
4, 8, 1, 9, 6, 3,
]
# number of occurrences of each digit from DATA
# type: dict[int,int]
result = ...
"""
* Assignment: Loop For Segmentation
* Type: class assignment
* Complexity: easy
* Lines of code: 10 lines
* Time: 8 min
English:
1. Count number of occurrences for digit in segments:
a. 'small' - digitst in range [0-3)
b. 'medium' - digitst in range [3-7)
c. 'large' - digitst in range [7-10)
2. Notation `[0-3)` - means, digits between 0 and 3, without 3 (left-side closed)
3. Run doctests - all must succeed
Polish:
1. Policz liczbę wystąpień cyfr w przedziałach:
a. 'small' - cyfry z przedziału <0-3)
b. 'medium' - cyfry z przedziału <3-7)
c. 'large' - cyfry z przedziału <7-10)
2. Zapis `<0-3)` - znaczy, cyfry od 0 do 3, bez 3 (lewostronnie domknięty)
3. Uruchom doctesty - wszystkie muszą się powieść
Tests:
>>> import sys; sys.tracebacklimit = 0
>>> assert result is not Ellipsis, \
'Assign your result to variable `result`'
>>> assert type(result) is dict, \
'Variable `result` has invalid type, should be dict'
>>> assert all(type(x) is str for x in result.keys())
>>> assert all(type(x) is int for x in result.values())
>>> result
{'small': 16, 'medium': 19, 'large': 15}
"""
DATA = [
1, 4, 6, 7, 4, 4, 4, 5, 1, 7, 0,
0, 6, 5, 0, 0, 9, 7, 0, 4, 4, 8,
2, 4, 0, 0, 1, 9, 1, 7, 8, 8, 9,
1, 3, 5, 6, 8, 2, 8, 1, 3, 9, 5,
4, 8, 1, 9, 6, 3,
]
# Number of digit occurrences in segments
# type: dict[str,int]
result = {'small': 0, 'medium': 0, 'large': 0}
"""
* Assignment: Loop For Newline
* Type: class assignment
* Complexity: easy
* Lines of code: 2 lines
* Time: 5 min
English:
1. Define `result: str`
2. Use `for` to iterate over `DATA`
3. Join lines of text with newline (`\n`) character
4. Do not use `str.join()`
5. Run doctests - all must succeed
Polish:
1. Zdefiniuj `result: str`
2. Użyj `for` do iterowania po `DATA`
3. Połącz linie tekstu znakiem końca linii (`\n`)
4. Nie używaj `str.join()`
5. Uruchom doctesty - wszystkie muszą się powieść
Tests:
>>> import sys; sys.tracebacklimit = 0
>>> from pprint import pprint
>>> assert result is not Ellipsis, \
'Assign your result to variable `result`'
>>> assert type(result) is str, \
'Variable `result` has invalid type, should be str'
>>> result.count('\\n')
3
>>> pprint(result)
('We choose to go to the Moon.\\n'
'We choose to go to the Moon in this decade and do the other things.\\n'
'Not because they are easy, but because they are hard.\\n')
"""
DATA = [
'We choose to go to the Moon.',
'We choose to go to the Moon in this decade and do the other things.',
'Not because they are easy, but because they are hard.',
]
# DATA joined with newline - \n
# type: str
result = ...
"""
* Assignment: Loop For Translate
* Type: class assignment
* Complexity: easy
* Lines of code: 2 lines
* Time: 5 min
English:
1. Define `result: str`
2. Use `for` to iterate over `DATA`
3. If letter is in `PL` then use conversion value as letter
4. Add letter to `result`
5. Run doctests - all must succeed
Polish:
1. Zdefiniuj `result: str`
2. Użyj `for` do iteracji po `DATA`
3. Jeżeli litera jest w `PL` to użyj przekonwertowanej wartości jako litera
4. Dodaj literę do `result`
5. Uruchom doctesty - wszystkie muszą się powieść
Tests:
>>> import sys; sys.tracebacklimit = 0
>>> assert result is not Ellipsis, \
'Assign your result to variable `result`'
>>> assert type(result) is str, \
'Variable `result` has invalid type, should be str'
>>> result
'zazolc gesla jazn'
"""
PL = {
'ą': 'a',
'ć': 'c',
'ę': 'e',
'ł': 'l',
'ń': 'n',
'ó': 'o',
'ś': 's',
'ż': 'z',
'ź': 'z',
}
DATA = 'zażółć gęślą jaźń'
# DATA with substituted PL diacritic chars to ASCII letters
# type: str
result = ...
"""
* Assignment: Loop For Months
* Type: class assignment
* Complexity: easy
* Lines of code: 4 lines
* Time: 5 min
English:
1. Convert `MONTH` into `result: dict[int,str]`:
a. Keys: month number
b. Values: month name
2. Do not use `enumerate`
3. Run doctests - all must succeed
Polish:
1. Przekonwertuj `MONTH` w `result: dict[int,str]`:
a. klucz: numer miesiąca
b. wartość: nazwa miesiąca
2. Nie używaj `enumerate`
3. Uruchom doctesty - wszystkie muszą się powieść
Tests:
>>> import sys; sys.tracebacklimit = 0
>>> from pprint import pprint
>>> assert result is not Ellipsis, \
'Assign your result to variable `result`'
>>> assert type(result) is dict, \
'Variable `result` has invalid type, should be dict'
>>> assert all(type(x) is int for x in result.keys())
>>> assert all(type(x) is str for x in result.values())
>>> assert all(x in result.keys() for x in range(1, 13))
>>> assert all(x in result.values() for x in MONTHS)
>>> 13 not in result
True
>>> 0 not in result
True
>>> pprint(result)
{1: 'January',
2: 'February',
3: 'March',
4: 'April',
5: 'May',
6: 'June',
7: 'July',
8: 'August',
9: 'September',
10: 'October',
11: 'November',
12: 'December'}
"""
MONTHS = ['January', 'February', 'March', 'April',
'May', 'June', 'July', 'August', 'September',
'October', 'November', 'December']
# Dict with month number and name. Start with 1
# type: dict[int,str]
result = ...